前回まで、OpenPoseを使って画像からの人の姿勢推定をしてたが、GoogleのMediaPipeでもそういったことができると聞いたことがあるので、試してみる。
参考
【MediaPipe】手の形状検出をやってみた | DevelopersIO
pipでpython環境に簡単にインストールできるよう。
MediaPipe概要確認
姿勢推定だけに限らず、できることが色々あるよう。
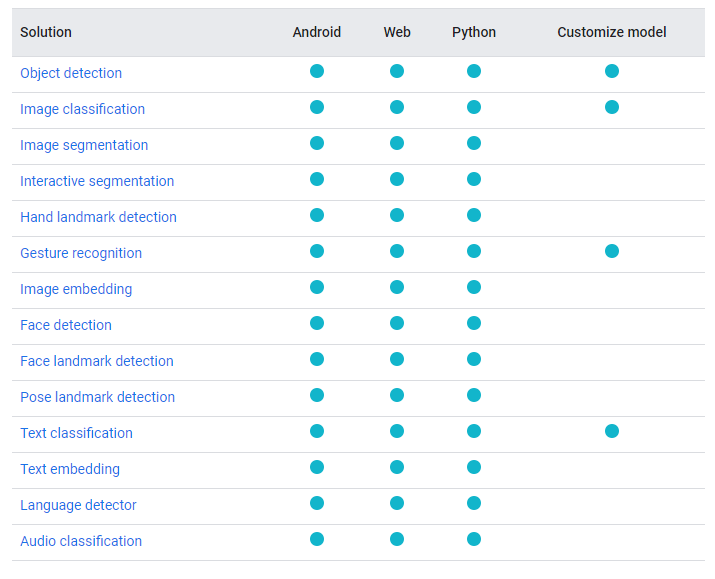
MediaPipeの姿勢推定を使ったこんな動画があったが、1度に1名までしか対応できないのか?
conda環境作成
MediaPipe試し用にconda環境を新しく用意しとく。
(base) PS C:\work\mediapipe_test> conda info -e
# conda environments:
#
base * C:\ProgramData\anaconda3
py311cv2 C:\ProgramData\anaconda3\envs\py311cv2
rtsp_streaming C:\Users\a\.conda\envs\rtsp_streaming
yolov5 C:\Users\a\.conda\envs\yolov5
(base) PS C:\work\mediapipe_test> conda create -n mediapipe python==3.9
Retrieving notices: ...working... done
Collecting package metadata (current_repodata.json): done
Solving environment: unsuccessful attempt using repodata from current_repodata.json, retrying with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 23.5.2
latest version: 23.7.3
Please update conda by running
$ conda update -n base -c defaults conda
Or to minimize the number of packages updated during conda update use
conda install conda=23.7.3
## Package Plan ##
environment location: C:\Users\a\.conda\envs\mediapipe
added / updated specs:
- python==3.9
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2023.08.22 | haa95532_0 123 KB
openssl-1.1.1v | h2bbff1b_0 5.5 MB
------------------------------------------------------------
Total: 5.6 MB
The following NEW packages will be INSTALLED:
ca-certificates pkgs/main/win-64::ca-certificates-2023.08.22-haa95532_0
openssl pkgs/main/win-64::openssl-1.1.1v-h2bbff1b_0
pip pkgs/main/win-64::pip-23.2.1-py39haa95532_0
python pkgs/main/win-64::python-3.9.0-h6244533_2
setuptools pkgs/main/win-64::setuptools-68.0.0-py39haa95532_0
sqlite pkgs/main/win-64::sqlite-3.41.2-h2bbff1b_0
tzdata pkgs/main/noarch::tzdata-2023c-h04d1e81_0
vc pkgs/main/win-64::vc-14.2-h21ff451_1
vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.27.29016-h5e58377_2
wheel pkgs/main/win-64::wheel-0.38.4-py39haa95532_0
Proceed ([y]/n)?
Downloading and Extracting Packages
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate mediapipe
#
# To deactivate an active environment, use
#
# $ conda deactivate
(base) PS C:\work\mediapipe_test>
MediaPipeのインストール。
ついでにOpenCVも入れておく。
(base) PS C:\work\mediapipe_test> conda activate mediapipe
(mediapipe) PS C:\work\mediapipe_test> pip install mediapipe
Collecting mediapipe
Obtaining dependency information for mediapipe from https://files.pythonhosted.org/packages/d4/22/7bf6bfff8a01ac38d9d744d07f90697997eab709e9a5ad1e0301202acb06/mediapipe-0.10.3-cp39-cp39-win_amd64.whl.metadata
Downloading mediapipe-0.10.3-cp39-cp39-win_amd64.whl.metadata (9.8 kB)
Collecting absl-py (from mediapipe)
Downloading absl_py-1.4.0-py3-none-any.whl (126 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 126.5/126.5 kB ? eta 0:00:00
Collecting attrs>=19.1.0 (from mediapipe)
Downloading attrs-23.1.0-py3-none-any.whl (61 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.2/61.2 kB ? eta 0:00:00
Collecting flatbuffers>=2.0 (from mediapipe)
Obtaining dependency information for flatbuffers>=2.0 from https://files.pythonhosted.org/packages/6f/12/d5c79ee252793ffe845d58a913197bfa02ae9a0b5c9bc3dc4b58d477b9e7/flatbuffers-23.5.26-py2.py3-none-any.whl.metadata
Downloading flatbuffers-23.5.26-py2.py3-none-any.whl.metadata (850 bytes)
Collecting matplotlib (from mediapipe)
Obtaining dependency information for matplotlib from https://files.pythonhosted.org/packages/c9/46/6cbaf20f5bd0e7c1d204b45b853c2cd317b303fada90245f2825ecca47de/matplotlib-3.7.2-cp39-cp39-win_amd64.whl.metadata
Downloading matplotlib-3.7.2-cp39-cp39-win_amd64.whl.metadata (5.8 kB)
Collecting numpy (from mediapipe)
Obtaining dependency information for numpy from https://files.pythonhosted.org/packages/df/18/181fb40f03090c6fbd061bb8b1f4c32453f7c602b0dc7c08b307baca7cd7/numpy-1.25.2-cp39-cp39-win_amd64.whl.metadata
Downloading numpy-1.25.2-cp39-cp39-win_amd64.whl.metadata (5.7 kB)
Collecting opencv-contrib-python (from mediapipe)
Obtaining dependency information for opencv-contrib-python from https://files.pythonhosted.org/packages/05/33/5a6436146bda09c69decc456cfb54f41d52fbcf558fe91e6df7bdde6cce0/opencv_contrib_python-4.8.0.76-cp37-abi3-win_amd64.whl.metadata
Downloading opencv_contrib_python-4.8.0.76-cp37-abi3-win_amd64.whl.metadata (20 kB)
Collecting protobuf<4,>=3.11 (from mediapipe)
Downloading protobuf-3.20.3-cp39-cp39-win_amd64.whl (904 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 904.2/904.2 kB 55.9 MB/s eta 0:00:00
Collecting sounddevice>=0.4.4 (from mediapipe)
Downloading sounddevice-0.4.6-py3-none-win_amd64.whl (199 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 199.7/199.7 kB 12.6 MB/s eta 0:00:00
Collecting CFFI>=1.0 (from sounddevice>=0.4.4->mediapipe)
Downloading cffi-1.15.1-cp39-cp39-win_amd64.whl (179 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 179.1/179.1 kB ? eta 0:00:00
Collecting contourpy>=1.0.1 (from matplotlib->mediapipe)
Obtaining dependency information for contourpy>=1.0.1 from https://files.pythonhosted.org/packages/a5/d6/80258c2759bd34abe267b5d3bc6300f7105aa70181b99d531283f7e7c79e/contourpy-1.1.0-cp39-cp39-win_amd64.whl.metadata
Downloading contourpy-1.1.0-cp39-cp39-win_amd64.whl.metadata (5.7 kB)
Collecting cycler>=0.10 (from matplotlib->mediapipe)
Using cached cycler-0.11.0-py3-none-any.whl (6.4 kB)
Collecting fonttools>=4.22.0 (from matplotlib->mediapipe)
Obtaining dependency information for fonttools>=4.22.0 from https://files.pythonhosted.org/packages/1b/6d/93121de94919bd072a93131167d7c6244eb26fe9f2f897ddfee8eb550ffa/fonttools-4.42.1-cp39-cp39-win_amd64.whl.metadata
Downloading fonttools-4.42.1-cp39-cp39-win_amd64.whl.metadata (154 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 154.1/154.1 kB 9.6 MB/s eta 0:00:00
Collecting kiwisolver>=1.0.1 (from matplotlib->mediapipe)
Obtaining dependency information for kiwisolver>=1.0.1 from https://files.pythonhosted.org/packages/ca/c1/1f986c8119c0c57c2bd71d1941da23332c38ee2c90117e46dff4358b70f7/kiwisolver-1.4.5-cp39-cp39-win_amd64.whl.metadata
Downloading kiwisolver-1.4.5-cp39-cp39-win_amd64.whl.metadata (6.5 kB)
Collecting packaging>=20.0 (from matplotlib->mediapipe)
Using cached packaging-23.1-py3-none-any.whl (48 kB)
Collecting pillow>=6.2.0 (from matplotlib->mediapipe)
Obtaining dependency information for pillow>=6.2.0 from https://files.pythonhosted.org/packages/8f/b8/1bf1012eee3059d150194d1fab148f553f3df42cf412e4e6656c772afad9/Pillow-10.0.0-cp39-cp39-win_amd64.whl.metadata
Downloading Pillow-10.0.0-cp39-cp39-win_amd64.whl.metadata (9.6 kB)
Collecting pyparsing<3.1,>=2.3.1 (from matplotlib->mediapipe)
Using cached pyparsing-3.0.9-py3-none-any.whl (98 kB)
Collecting python-dateutil>=2.7 (from matplotlib->mediapipe)
Using cached python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
Collecting importlib-resources>=3.2.0 (from matplotlib->mediapipe)
Obtaining dependency information for importlib-resources>=3.2.0 from https://files.pythonhosted.org/packages/25/d4/592f53ce2f8dde8be5720851bd0ab71cc2e76c55978e4163ef1ab7e389bb/importlib_resources-6.0.1-py3-none-any.whl.metadata
Downloading importlib_resources-6.0.1-py3-none-any.whl.metadata (4.0 kB)
Collecting pycparser (from CFFI>=1.0->sounddevice>=0.4.4->mediapipe)
Downloading pycparser-2.21-py2.py3-none-any.whl (118 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 118.7/118.7 kB ? eta 0:00:00
Collecting zipp>=3.1.0 (from importlib-resources>=3.2.0->matplotlib->mediapipe)
Obtaining dependency information for zipp>=3.1.0 from https://files.pythonhosted.org/packages/8c/08/d3006317aefe25ea79d3b76c9650afabaf6d63d1c8443b236e7405447503/zipp-3.16.2-py3-none-any.whl.metadata
Downloading zipp-3.16.2-py3-none-any.whl.metadata (3.7 kB)
Collecting six>=1.5 (from python-dateutil>=2.7->matplotlib->mediapipe)
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Downloading mediapipe-0.10.3-cp39-cp39-win_amd64.whl (50.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50.2/50.2 MB 46.9 MB/s eta 0:00:00
Downloading flatbuffers-23.5.26-py2.py3-none-any.whl (26 kB)
Downloading matplotlib-3.7.2-cp39-cp39-win_amd64.whl (7.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.5/7.5 MB 80.6 MB/s eta 0:00:00
Downloading numpy-1.25.2-cp39-cp39-win_amd64.whl (15.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 15.6/15.6 MB 81.8 MB/s eta 0:00:00
Downloading opencv_contrib_python-4.8.0.76-cp37-abi3-win_amd64.whl (44.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.8/44.8 MB 54.4 MB/s eta 0:00:00
Downloading contourpy-1.1.0-cp39-cp39-win_amd64.whl (429 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 429.4/429.4 kB ? eta 0:00:00
Downloading fonttools-4.42.1-cp39-cp39-win_amd64.whl (2.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 44.7 MB/s eta 0:00:00
Downloading importlib_resources-6.0.1-py3-none-any.whl (34 kB)
Downloading kiwisolver-1.4.5-cp39-cp39-win_amd64.whl (56 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.2/56.2 kB ? eta 0:00:00
Downloading Pillow-10.0.0-cp39-cp39-win_amd64.whl (2.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.5/2.5 MB 78.2 MB/s eta 0:00:00
Downloading zipp-3.16.2-py3-none-any.whl (7.2 kB)
Installing collected packages: flatbuffers, zipp, six, pyparsing, pycparser, protobuf, pillow, packaging, numpy, kiwisolver, fonttools, cycler, attrs, absl-py, python-dateutil, opencv-contrib-python, importlib-resources, contourpy, CFFI, sounddevice, matplotlib, mediapipe
Successfully installed CFFI-1.15.1 absl-py-1.4.0 attrs-23.1.0 contourpy-1.1.0 cycler-0.11.0 flatbuffers-23.5.26 fonttools-4.42.1 importlib-resources-6.0.1 kiwisolver-1.4.5 matplotlib-3.7.2 mediapipe-0.10.3 numpy-1.25.2 opencv-contrib-python-4.8.0.76 packaging-23.1 pillow-10.0.0 protobuf-3.20.3 pycparser-2.21 pyparsing-3.0.9 python-dateutil-2.8.2 six-1.16.0 sounddevice-0.4.6 zipp-3.16.2
(mediapipe) PS C:\work\mediapipe_test>
(mediapipe) PS C:\work\mediapipe_test>
(mediapipe) PS C:\work\mediapipe_test> pip install opencv-python
Collecting opencv-python
Obtaining dependency information for opencv-python from https://files.pythonhosted.org/packages/fb/c4/f574ba6f04e6d7bf8c38d23e7a52389566dd7631fee0bcdd79ea07ef2dbf/opencv_python-4.8.0.76-cp37-abi3-win_amd64.whl.metadata
Using cached opencv_python-4.8.0.76-cp37-abi3-win_amd64.whl.metadata (20 kB)
Requirement already satisfied: numpy>=1.17.0 in c:\users\akihiro\.conda\envs\mediapipe\lib\site-packages (from opencv-python) (1.25.2)
Using cached opencv_python-4.8.0.76-cp37-abi3-win_amd64.whl (38.1 MB)
Installing collected packages: opencv-python
Successfully installed opencv-python-4.8.0.76
(mediapipe) PS C:\work\mediapipe_test>
以降はJupyterで実行、記述した内容。
まずMOT16で試し。
参考サイトとか公式サイトとか見ると、そこそこコードを書かないと動かせないよう。
コピペすればいいだけではあるが。
公式のサンプルをもとに動かしてみる。
モデルファイルをダウンロードするためのwgetコマンドはWindowsですぐに使えなかったので、ブラウザで開いてダウンロードした。
#@markdown To better demonstrate the Pose Landmarker API, we have created a set of visualization tools that will be used in this colab. These will draw the landmarks on a detect person, as well as the expected connections between those markers. from mediapipe import solutions from mediapipe.framework.formats import landmark_pb2 import numpy as np def draw_landmarks_on_image(rgb_image, detection_result): pose_landmarks_list = detection_result.pose_landmarks annotated_image = np.copy(rgb_image) # Loop through the detected poses to visualize. for idx in range(len(pose_landmarks_list)): pose_landmarks = pose_landmarks_list[idx] # Draw the pose landmarks. pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList() pose_landmarks_proto.landmark.extend([ landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in pose_landmarks ]) solutions.drawing_utils.draw_landmarks( annotated_image, pose_landmarks_proto, solutions.pose.POSE_CONNECTIONS, solutions.drawing_styles.get_default_pose_landmarks_style()) return annotated_image
import cv2 from matplotlib import pyplot as plt %matplotlib inline
def plot_MOT16_image(img): img0 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img0), plt.xticks([]), plt.yticks([]) plt.show() print('MOT16 - https://motchallenge.net/data/MOT16/')
img_path = '../MOT16/train/MOT16-09/img1/000100.jpg'
img = cv2.imread(img_path)
plot_MOT16_image(img)

# STEP 1: Import the necessary modules. import mediapipe as mp from mediapipe.tasks import python from mediapipe.tasks.python import vision # STEP 2: Create an PoseLandmarker object. base_options = python.BaseOptions(model_asset_path='pose_landmarker_heavy.task') options = vision.PoseLandmarkerOptions( base_options=base_options, output_segmentation_masks=True) detector = vision.PoseLandmarker.create_from_options(options) # STEP 3: Load the input image. image = mp.Image.create_from_file(img_path) # STEP 4: Detect pose landmarks from the input image. detection_result = detector.detect(image) # STEP 5: Process the detection result. In this case, visualize it. annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) plot_MOT16_image(cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))

オプションで最大検出人数も設定できるよう。
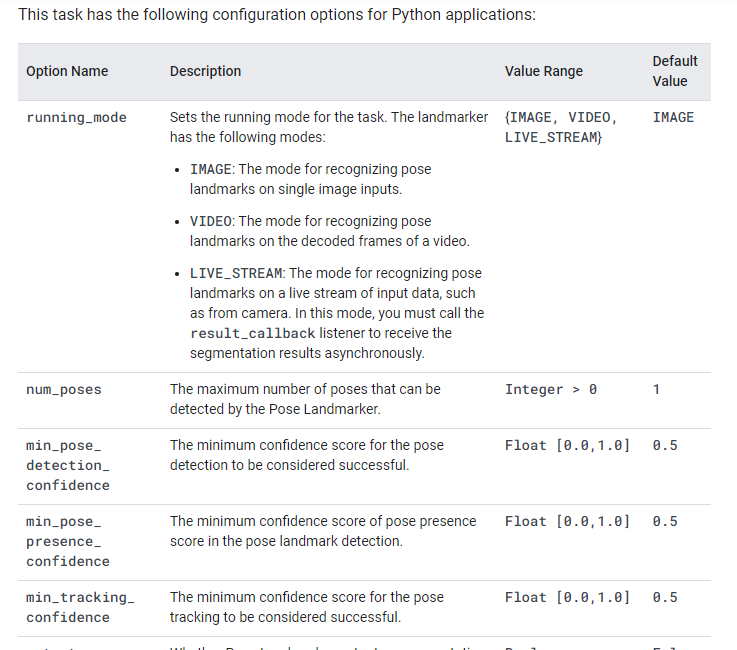
options = vision.PoseLandmarkerOptions(
base_options=base_options,
output_segmentation_masks=True,
num_poses=10)
detector = vision.PoseLandmarker.create_from_options(options)
# STEP 3: Load the input image. image = mp.Image.create_from_file(img_path) # STEP 4: Detect pose landmarks from the input image. detection_result = detector.detect(image) # STEP 5: Process the detection result. In this case, visualize it. annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) plot_MOT16_image(cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR))

len(detection_result.pose_landmarks)
1
1人しか認識してくれてない?
とりあえず全フレームやってみるか。
そして動画ファイルにする。
mot16_09_list = os.listdir('../MOT16/train/MOT16-09/img1/') codec = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') writer = cv2.VideoWriter('MOT16-09_out-1.avi',codec, 30, (1920, 1080)) for img_file in mot16_09_list: img_path = os.path.join('../MOT16/train/MOT16-09/img1/', img_file) image = mp.Image.create_from_file(img_path) detection_result = detector.detect(image) annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR) writer.write(annotated_image) writer.release()
処理時間は1m13.7s。
OpenPoseより断然速くなっている。
タスクマネージャーを見ると、CPUだけで動いていた。

出力動画を見ると、複数人同時に姿勢推定されてることもあった。 単に認識精度とかの問題か。


min_pose_detection_confidenceで認識できたかどうかの閾値を設定できるのでやってみる。
デフォルトで0.5なので、0.25ぐらいにしてみるか。
options = vision.PoseLandmarkerOptions(
base_options=base_options,
output_segmentation_masks=True,
num_poses=10,
min_pose_detection_confidence=0.25)
detector = vision.PoseLandmarker.create_from_options(options)
mot16_09_list = os.listdir('../MOT16/train/MOT16-09/img1/') codec = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') writer = cv2.VideoWriter('MOT16-09_out-2.avi',codec, 30, (1920, 1080)) for img_file in mot16_09_list: img_path = os.path.join('../MOT16/train/MOT16-09/img1/', img_file) image = mp.Image.create_from_file(img_path) detection_result = detector.detect(image) annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR) writer.write(annotated_image) writer.release()
処理時間は1m22.7s。
ちょっとだけ長くなった?


結果が劇的に変わったわけではなかった。
やっぱり性能自体はOpenPoseのほうがいいのか。
その代わり処理はとても軽い。
自分のピアノ動画でやってみる。
piano_movie = cv2.VideoCapture('C:/Users/a/Downloads/2023-08-31 07.48.56.mov')
piano_movie.isOpened()
True
writer = cv2.VideoWriter('piano-out.avi',codec, 15, (2304, 1296)) ret, img = piano_movie.read() while ret: image = mp.Image(image_format=mp.ImageFormat.SRGB, data=img) detection_result = detector.detect(image) annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) cv2.imshow('img', annotated_image) cv2.waitKey(1) writer.write(annotated_image) ret, img = piano_movie.read() writer.release()
cv2.destroyAllWindows()
結果。



かなりダメダメ。
hand_landmarker使う
pose_landmarkerを使ってるのが間違いかも。
hand_landmarkerでやってみる。
(手だけでなく、腕全体の動きも見たいが、そこまではやってくれなさそう。)
モデルファイル
hand_landmarkerでも、それ用のモデルファイルをダウンロードする。
結果の可視化
公式サンプルを見ると、pose_landmarkerと同じような可視化処理が、同じ名前(draw_landmarks_on_image)で定義されている。
手の可視化用に、若干違いがあるようなので、別名で定義しておく。
MARGIN = 10 # pixels FONT_SIZE = 1 FONT_THICKNESS = 1 HANDEDNESS_TEXT_COLOR = (88, 205, 54) # vibrant green def draw_hand_landmarks_on_image(rgb_image, detection_result): hand_landmarks_list = detection_result.hand_landmarks handedness_list = detection_result.handedness annotated_image = np.copy(rgb_image) # Loop through the detected hands to visualize. for idx in range(len(hand_landmarks_list)): hand_landmarks = hand_landmarks_list[idx] handedness = handedness_list[idx] # Draw the hand landmarks. hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList() hand_landmarks_proto.landmark.extend([ landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in hand_landmarks ]) solutions.drawing_utils.draw_landmarks( annotated_image, hand_landmarks_proto, solutions.hands.HAND_CONNECTIONS, solutions.drawing_styles.get_default_hand_landmarks_style(), solutions.drawing_styles.get_default_hand_connections_style()) # Get the top left corner of the detected hand's bounding box. height, width, _ = annotated_image.shape x_coordinates = [landmark.x for landmark in hand_landmarks] y_coordinates = [landmark.y for landmark in hand_landmarks] text_x = int(min(x_coordinates) * width) text_y = int(min(y_coordinates) * height) - MARGIN # Draw handedness (left or right hand) on the image. cv2.putText(annotated_image, f"{handedness[0].category_name}", (text_x, text_y), cv2.FONT_HERSHEY_DUPLEX, FONT_SIZE, HANDEDNESS_TEXT_COLOR, FONT_THICKNESS, cv2.LINE_AA) return annotated_image
hand_base_options = python.BaseOptions(model_asset_path='hand_landmarker.task') hand_options = vision.HandLandmarkerOptions(base_options=hand_base_options, num_hands=2) hand_detector = vision.HandLandmarker.create_from_options(hand_options)
同じくピアノ動画でやってみる。
piano_movie = cv2.VideoCapture('C:/Users/a/Downloads/2023-08-31 07.48.56.mov')
writer = cv2.VideoWriter('piano-out-2.avi',codec, 15, (2304, 1296)) ret, img = piano_movie.read() while ret: image = mp.Image(image_format=mp.ImageFormat.SRGB, data=img) detection_result = hand_detector.detect(image) annotated_image = draw_hand_landmarks_on_image(image.numpy_view(), detection_result) cv2.imshow('img', annotated_image) cv2.waitKey(1) writer.write(annotated_image) ret, img = piano_movie.read() writer.release() cv2.destroyAllWindows()
cv2.destroyAllWindows()
手の骨格が全く認識されず…

オプション見直し
うまくいかなかったので、オプションを見直して再実施。
https://developers.google.com/mediapipe/solutions/vision/hand_landmarker#configurations_options
Hand landmarks detection guide for Python | MediaPipe | Google for Developers
- オプション設定時、
runnning_mode引数で、静止画(IMAGE)、動画(VIDEO)かストリームか(LIVE_STREAM)の指定ができる。
結局与えるのは1枚の画像だが、前のフレームの情報を何かしら使うということだろうか。 - 上の定数は、
mp.tasks.vision.RunningModeの中で定義されてる。 VIDEOだと、検出のときにdetectでなくdetect_for_video()を使わないといけないdetect_for_video()では、timestamp_ms引数がある。整数で、フレームごとの時刻を与えたらいいということか。
Args:
image: MediaPipe Image.
timestamp_ms: The timestamp of the input video frame in milliseconds.
image_processing_options: Options for image processing.
hand_base_options = python.BaseOptions(model_asset_path='hand_landmarker.task') hand_options = vision.HandLandmarkerOptions(base_options=hand_base_options, running_mode=mp.tasks.vision.RunningMode.VIDEO, # min_hand_presence_confidence=0.1, num_hands=2) hand_detector = vision.HandLandmarker.create_from_options(hand_options)
piano_movie = cv2.VideoCapture('C:/Users/a/Downloads/2023-08-31 07.48.56.mov')
w = int(piano_movie.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(piano_movie.get(cv2.CAP_PROP_FRAME_HEIGHT)) writer = cv2.VideoWriter('piano-out-3.avi',codec, 15, (w, h)) ret, img = piano_movie.read() t = 0 while ret: image = mp.Image(image_format=mp.ImageFormat.SRGB, data=img) detection_result = hand_detector.detect_for_video(image, t) annotated_image = draw_hand_landmarks_on_image(image.numpy_view(), detection_result) cv2.imshow('img', annotated_image) cv2.waitKey(1) writer.write(annotated_image) ret, img = piano_movie.read() t += int(1000/15) writer.release() cv2.destroyAllWindows()
結果、特に変わらなかった。
サンプル画像で試し
やっぱりうまくいかないので、サンプル通りの画像をダウンロードして、極力GitHubのサンプルコード通りやってみる。
https://storage.googleapis.com/mediapipe-tasks/hand_landmarker/woman_hands.jpg
{kind=link}
hand_base_options = python.BaseOptions(model_asset_path='hand_landmarker.task') hand_options = vision.HandLandmarkerOptions(base_options=hand_base_options, num_hands=2) hand_detector = vision.HandLandmarker.create_from_options(hand_options)
# STEP 3: Load the input image. image = mp.Image.create_from_file("woman_hands.jpg") # STEP 4: Detect hand landmarks from the input image. detection_result = hand_detector.detect(image) # STEP 5: Process the classification result. In this case, visualize it. annotated_image = draw_hand_landmarks_on_image(image.numpy_view(), detection_result) cv2.imwrite('woman_hands_out.jpg', cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR)) plt.imshow(annotated_image), plt.xticks([]), plt.yticks([]) plt.show()

ちゃんとできてる。
もしかして色フォーマット間違えてた?
まずpose_landmarkerでやり直してみる。
piano_movie = cv2.VideoCapture('C:/Users/a/Downloads/2023-08-31 07.48.56.mov')
w = int(piano_movie.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(piano_movie.get(cv2.CAP_PROP_FRAME_HEIGHT)) writer = cv2.VideoWriter('piano-out-4.avi',codec, 15, (w, h)) ret, img = piano_movie.read() while ret: image = mp.Image(image_format=mp.ImageFormat.SRGB, data=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) detection_result = detector.detect(image) annotated_image = draw_landmarks_on_image(image.numpy_view(), detection_result) annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR) cv2.imshow('img', annotated_image) cv2.waitKey(1) writer.write(annotated_image) ret, img = piano_movie.read() writer.release() cv2.destroyAllWindows()
若干結果が変わったような。
でもダメダメなことに変わりはない。

次、hand_landmarkerで。
hand_base_options = python.BaseOptions(model_asset_path='hand_landmarker.task') hand_options = vision.HandLandmarkerOptions(base_options=hand_base_options, num_hands=2) hand_detector = vision.HandLandmarker.create_from_options(hand_options)
piano_movie = cv2.VideoCapture('C:/Users/a/Downloads/2023-08-31 07.48.56.mov')
w = int(piano_movie.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(piano_movie.get(cv2.CAP_PROP_FRAME_HEIGHT)) writer = cv2.VideoWriter('piano-out-5.avi',codec, 15, (w, h)) ret, img = piano_movie.read() while ret: image = mp.Image(image_format=mp.ImageFormat.SRGB, data=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) detection_result = hand_detector.detect(image) annotated_image = draw_hand_landmarks_on_image(image.numpy_view(), detection_result) annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_RGB2BGR) cv2.imshow('img', annotated_image) cv2.waitKey(1) writer.write(annotated_image) ret, img = piano_movie.read() writer.release() cv2.destroyAllWindows()
手が検出された。
手前の手はよく認識されるが、奥の手はたまにしか認識されない。
あと、rightとleftと書かれてるが、逆になってるような。



以上
MediaPipeは、処理は速いが性能がよくないよう。
パラメータ調整次第かもしれないが。
調べると他にも姿勢推定、骨格推定のアルゴリズムがあるようだったので、試していきたい。