春のパン祭り点数集計、前回で最後のつもりでしたが、1つ高速化の手段を思いついたので、もうちょっとがんばります。
変更内容
前に処理の様子を見た感じ、ICPアルゴリズムで時間がかかっているようでした。
テンプレートの輪郭点と対象輪郭の輪郭点間の最近傍点を探索するのに、輪郭上の全点間の距離を計算していたので、それが時間がかかったのかと。
思い付いたことは、
- 輪郭の点データは、輪郭の周に沿った順番に並んでいたので、全部の点からの探索をしなくてもいいのでは?
ということ。
処理の変更を実装して色々デバッグしましたが、なんとかうまくいったので、以下記載します。
下準備
春のパン祭り点数集計スクリプトの読み込み、テンプレートデータとSVMデータの読み込みを行います。
スクリプトのうち、ICP処理関数を変更します。
例によって、スクリプトファイル読み込みだと関数の上書きがうまくいかなかったので、以下に全部コピペします。
ブログが読みづらくなっちゃいますが…
スクリプト読み込み
前とほぼ同じスクリプトですが、calc_harupan()関数で、一致度ベクトルを表示させる変更が入っています。
###################################################### # Importing libraries ###################################################### from ctypes import resize import cv2 import numpy as np from matplotlib import pyplot as plt import math import copy import random import json ###################################################### # Detecting contours ###################################################### def reduce_resolution(img, res_th=800): h, w, chs = img.shape if h > res_th or w > res_th: k = float(res_th)/h if w > h else float(res_th)/w else: k = 1.0 rtn_img = cv2.resize(img, None, fx=k, fy=k, interpolation=cv2.INTER_AREA) return rtn_img def harupan_binarize(img, sat_th=100): hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # Convert hue value (rotation, mask by saturation) hsv[:,:,0] = np.where(hsv[:,:,0] < 50, hsv[:,:,0]+180, hsv[:,:,0]) hsv[:,:,0] = np.where(hsv[:,:,1] < sat_th, 0, hsv[:,:,0]) # Thresholding with cv2.inRange() binary_img = cv2.inRange(hsv[:,:,0], 135, 190) return binary_img def detect_candidate_contours(image, res_th=800, sat_th=100): img = reduce_resolution(image, res_th) binimg = harupan_binarize(img, sat_th) # Retrieve all points on the contours (cv2.CHAIN_APPROX_NONE) contours, hierarchy = cv2.findContours(binimg, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) if len(contours) == 0: return contours, img # Pick up contours that have no parents indices = [i for i,hier in enumerate(hierarchy[0,:,:]) if hier[3] == -1] # Pick up contours that reside in above contours indices = [i for i,hier in enumerate(hierarchy[0,:,:]) if (hier[3] in indices) and (hier[2] == -1) ] contours = [contours[i] for i in indices] contours = [ctr for ctr in contours if cv2.contourArea(ctr) > float(res_th)*float(res_th)/4000] return contours, img # image: Entire image containing multiple contours # contours: Contours contained in "image" (Retrieved by cv2.findContours(), the origin is same as "image") def refine_contours(image, contours): subctrs = [] subimgs = [] binimgs = [] thresholds = [] n_ctrs = [] for ctr in contours: img, _ = create_contour_area_image(image, ctr) # Thresholding using G value in BGR format thresh, binimg = cv2.threshold(img[:,:,1], 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) # Add black region around thresholded image, to detect contours correctly binimg = cv2.copyMakeBorder(binimg, 2,2,2,2, cv2.BORDER_CONSTANT, 0) ctrs2, _ = cv2.findContours(binimg, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) max_len = 0 for ctr2 in ctrs2: if max_len <= ctr2.shape[0]: max_ctr = ctr2 max_len = ctr2.shape[0] subctrs += [max_ctr] subimgs += [img] binimgs += [binimg] thresholds += [thresh] n_ctrs += [len(ctrs2)] debug_info = (binimgs, thresholds, n_ctrs) return subctrs, subimgs, debug_info ###################################################### # Auxiliary functions ###################################################### def create_contour_area_image(img, ctr): x,y,w,h = cv2.boundingRect(ctr) rtn_img = img[y:y+h,x:x+w,:].copy() rtn_ctr = ctr.copy() origin = np.array([x,y]) for c in rtn_ctr: c[0,:] -= origin return rtn_img, rtn_ctr # ctr: Should be output of create_contour_area_image() (Origin of points is the origin of bounding box) # img_shape: Optional, tuple of (image_height, image_width), if omitted, calculated from ctr def create_solid_contour(ctr, img_shape=(int(0),int(0))): if img_shape == (int(0),int(0)): _,_,w,h = cv2.boundingRect(ctr) else: h,w = img_shape img = np.zeros((h,w), 'uint8') img = cv2.drawContours(img, [ctr], -1, 255, -1) return img # ctr: Should be output of create_contour_area_image() (Origin of points is the origin of bounding box) def create_upright_solid_contour(ctr): ctr2 = ctr.copy() (cx,cy),(w,h),angle = cv2.minAreaRect(ctr2) M = cv2.getRotationMatrix2D((cx,cy), angle, 1) for i in range(ctr2.shape[0]): ctr2[i,0,:] = ( M @ np.array([ctr2[i,0,0], ctr2[i,0,1], 1]) ).astype('int') rect = cv2.boundingRect(ctr2) img = np.zeros((rect[3],rect[2]), 'uint8') ctr2 -= rect[0:2] M[:,2] -= rect[0:2] img = cv2.drawContours(img, [ctr2], -1, 255,-1) return img, M, ctr2 ###################################################### # Dataset classes ###################################################### class contour_dataset: def __init__(self, ctr): self.ctr = ctr.copy() self.rrect = cv2.minAreaRect(ctr) self.box = cv2.boxPoints(self.rrect) self.solid = create_solid_contour(ctr) n = 100 if n >= ctr.shape[0]: self.pts = np.array([p for p in ctr[:,0,:]]) else: r = n / ctr.shape[0] self.pts = np.zeros((100,2), 'int') pts = [] for i in range(ctr.shape[0]): f = math.modf(i*r)[0] if (f <= r/2) or (f > 1.0 - r/2): pts += [ctr[i,0,:]] self.pts = np.array(pts) class template_dataset: def __init__(self, ctr, num, selected_idx=[0]): self.ctr = ctr.copy() self.num = num self.rrect = cv2.minAreaRect(ctr) self.box = cv2.boxPoints(self.rrect) if num == 0: self.solid,_,_ = create_upright_solid_contour(ctr) else: self.solid = create_solid_contour(ctr) self.pts = np.array([ctr[idx,0,:] for idx in selected_idx]) ###################################################### # ICP ###################################################### # pts: list of 2D points, or ndarray of shape (n,2) # query: 2D point to find nearest neighbor def find_nearest_neighbor(pts, query): min_distance_sq = float('inf') min_idx = 0 for i, p in enumerate(pts): d = np.dot(query - p, query - p) if(d < min_distance_sq): min_distance_sq = d min_idx = i return min_idx, np.sqrt(min_distance_sq) # src, dst: ndarray, shape is (n,2) (n: number of points) def estimate_affine_2d(src, dst): n = min(src.shape[0], dst.shape[0]) x = dst[0:n].flatten() A = np.zeros((2*n,6)) for i in range(n): A[i*2,0] = src[i,0] A[i*2,1] = src[i,1] A[i*2,2] = 1 A[i*2+1,3] = src[i,0] A[i*2+1,4] = src[i,1] A[i*2+1,5] = 1 M = np.linalg.inv(A.T @ A) @ A.T @ x return M.reshape([2,3]) # Find optimum affine matrix using ICP algorithm # src_pts: ndarray, shape is (n_s,2) (n_s: number of points) # dst_pts: ndarray, shape is (n_d,2) (n_d: number of points, n_d should be larger or equal to n_s) # initial_matrix: ndarray, shape is (2,3) def icp(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]])): default_affine_matrix = np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]) if dst_pts.shape[0] < src_pts.shape[0]: # print("icp: Insufficient destination points") return default_affine_matrix, False if initial_matrix.shape != (2,3): print("icp: Illegal shape of initial_matrix") return default_affine_matrix, False M = initial_matrix # Store indices of the nearest neighbor point of dst_pts to the converted point of src_pts nn_idx = [] for i in range(max_iter): nn_idx_tmp = [] dst_pts_list = [p for p in dst_pts] idx_list = list(range(0,dst_pts.shape[0])) for p in src_pts: p2 = M @ np.array([p[0], p[1], 1]) idx, d = find_nearest_neighbor(dst_pts_list, p2) nn_idx_tmp += [idx_list[idx]] del dst_pts_list[idx] del idx_list[idx] if nn_idx != [] and nn_idx == nn_idx_tmp: break dst_pts2 = np.zeros_like(src_pts) for j,idx in enumerate(nn_idx_tmp): dst_pts2[j,:] = dst_pts[idx,:] M = estimate_affine_2d(src_pts, dst_pts2) nn_idx = nn_idx_tmp if i == max_iter -1: return M, False return M, True ###################################################### # Calculating similarity and determining the number ###################################################### def binary_image_similarity(img1, img2): if img1.shape != img2.shape: print('binary_image_similarity: Different image size') return 0.0 xor_img = cv2.bitwise_xor(img1, img2) return 1.0 - np.float(np.count_nonzero(xor_img)) / (img1.shape[0]*img2.shape[1]) # src, dst: contour_dataset or template_dataset (holding member variables box, solid) def get_transform_by_rotated_rectangle(src, dst): # Rotated patterns are created when starting index is slided dst_box2 = np.vstack([dst.box, dst.box]) max_similarity = 0.0 max_converted_img = np.zeros((dst.solid.shape[1], dst.solid.shape[0]), 'uint8') for i in range(4): M = cv2.getAffineTransform(src.box[0:3], dst_box2[i:i+3]) converted_img = cv2.warpAffine(src.solid, M, dsize=(dst.solid.shape[1], dst.solid.shape[0]), flags=cv2.INTER_NEAREST) similarity = binary_image_similarity(converted_img, dst.solid) if similarity > max_similarity: M_rtn = M max_similarity = similarity max_converted_img = converted_img return M_rtn, max_similarity, max_converted_img def get_similarity_with_template(target_data, template_data, sim_th_high=0.95, sim_th_low=0.7): _,(w1,h1), _ = target_data.rrect _,(w2,h2), _ = template_data.rrect r = w1/h1 if w1 < h1 else h1/w1 r = r * h2/w2 if w2 < h2 else r * w2/h2 M, sim_init, _ = get_transform_by_rotated_rectangle(template_data, target_data) if sim_init > sim_th_high or sim_init < sim_th_low or r > 1.4 or r < 0.7: dsize = (template_data.solid.shape[1], template_data.solid.shape[0]) flags = cv2.INTER_NEAREST|cv2.WARP_INVERSE_MAP converted_img = cv2.warpAffine(target_data.solid, M, dsize=dsize, flags=flags) return sim_init, converted_img M, _ = icp(template_data.pts, target_data.pts, initial_matrix=M) Minv = cv2.invertAffineTransform(M) converted_ctr = np.zeros_like(target_data.ctr) for i in range(target_data.ctr.shape[0]): converted_ctr[i,0,:] = (Minv[:,0:2] @ target_data.ctr[i,0,:]) + Minv[:,2] converted_img = create_solid_contour(converted_ctr, img_shape=template_data.solid.shape) val = binary_image_similarity(converted_img, template_data.solid) return val, converted_img def get_similarity_with_template_zero(target_data, template_data): dsize = (template_data.solid.shape[1], template_data.solid.shape[0]) converted_img = cv2.resize(target_data.solid, dsize=dsize, interpolation=cv2.INTER_NEAREST) val = binary_image_similarity(converted_img, template_data.solid) return val, converted_img def get_similarities(target, templates): similarities = [] converted_imgs = [] for tmpl in templates: if tmpl.num == 0: sim,converted_img = get_similarity_with_template_zero(target, tmpl) else: sim,converted_img = get_similarity_with_template(target, tmpl) similarities += [sim] converted_imgs += [converted_img] return similarities, converted_imgs def calc_harupan(img, templates, svm): ctrs, resized_img = detect_candidate_contours(img, sat_th=50) # print('Number of candidates: ', len(ctrs)) if len(ctrs) == 0: return 0.0, resized_img subctrs, _, _ = refine_contours(resized_img, ctrs) subctr_datasets = [contour_dataset(ctr) for ctr in subctrs] ######## #### Simple code # similarities = [get_similarities(d, templates)[0] for d in subctr_datasets] #### Code printing progress similarities = [] for i,d in enumerate(subctr_datasets): print(i, end=' ') similarities += [get_similarities(d, templates)[0]] print(similarities[-1]) print('') print('') ####### _, result = svm.predict(np.array(similarities, 'float32')) result = result.astype('int') score = 0.0 texts = {0:'0', 1:'1', 2:'2', 3:'3', 5:'.5'} font = cv2.FONT_HERSHEY_SIMPLEX for res, ctr in zip(result, ctrs): if res[0] == 5: score += 0.5 elif res[0] != -1: score += res[0] # Annotating recognized numbers for confirmation if res[0] != -1: resized_img = cv2.drawContours(resized_img, [ctr], -1, (0,255,0), 3) x,y,_,_ = cv2.boundingRect(ctr) resized_img = cv2.putText(resized_img, texts[res[0]], (x,y), font, 1, (230,230,0), 5) return score, resized_img ###################################################### # Loading template data and SVM model ###################################################### def load_svm(filename): return cv2.ml.SVM_load(filename) def load_templates(filename): with open(filename, mode='r') as f: load_data = json.load(f) templates_rtn = [] for d in load_data: templates_rtn += [template_dataset(np.array(d['ctr']), d['num'], d['pts'])] return templates_rtn
テンプレートデータ、SVMデータ読み込み
svm = load_svm('harupan_data/harupan_svm_220412.dat') templates2019 = load_templates('harupan_data/templates2019.json') templates2020 = load_templates('harupan_data/templates2020.json') templates2021 = load_templates('harupan_data/templates2021.json')
ついでに。
%matplotlib inline
処理変更
今回のICP処理では、テンプレートの輪郭点(ある程度間引いているので、点数少なめ)について、画像上で検出した輪郭上の輪郭点の中から最近傍の点を探して、それをマッチング点としてアフィン変換行列を推定しています。
この最近傍点探索処理を、以下のように変更します。
- 最初の1点は、対象輪郭の全点から最近傍点を探す
- 2点目以降は、前のマッチング点周辺の所定の範囲の点から最近傍点を探す
ICP処理関数の引数として、探索範囲を示すsearch_rangeを追加します。
まずは0.5に設定して、対象輪郭点のうち半分からの探索になるようにします。
ICP処理時間が半分になることを期待。
この引数を変えて試してみることを考えると、ICP関数は2段構えにしておいたほうがいいかも。
まずはデバッグ表示を色々付けた状態で。
def create_pts_image(pts): ctr = np.zeros((len(pts), 1, 2), 'int') for i,p in enumerate(pts): ctr[i,0,:] = p x,y,w,h = cv2.boundingRect(ctr) xe = x+w ye = y+h img = np.zeros((ye,xe,3), 'uint8') for i,p in enumerate(pts): cv2.drawMarker(img, p, (0,255,0), markerType=cv2.MARKER_CROSS, markerSize=3) cv2.drawMarker(img, pts[0], (255,0,0), markerType=cv2.MARKER_CROSS, markerSize=3) return img # Find optimum affine matrix using ICP algorithm # src_pts: ndarray, shape is (n_s,2) (n_s: number of points) # dst_pts: ndarray, shape is (n_d,2) (n_d: number of points, n_d should be larger or equal to n_s) # initial_matrix: ndarray, shape is (2,3) def icp(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]])): search_range = 0.5 return icp_sub(src_pts, dst_pts, max_iter=max_iter, initial_matrix=initial_matrix, search_range=search_range) # Find optimum affine matrix using ICP algorithm # src_pts: ndarray, shape is (n_s,2) (n_s: number of points) # dst_pts: ndarray, shape is (n_d,2) (n_d: number of points, n_d should be larger or equal to n_s) # initial_matrix: ndarray, shape is (2,3) # search_range: float number, 0.0 ~ 1.0, the range to search nearest neighbor, 1.0 -> Search in all dst_pts def icp_sub(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]), search_range=0.5): default_affine_matrix = np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]) n_dst = dst_pts.shape[0] n_src = src_pts.shape[0] if n_dst < n_src: # print("icp: Insufficient destination points") return default_affine_matrix, False if initial_matrix.shape != (2,3): print("icp: Illegal shape of initial_matrix") return default_affine_matrix, False n_search = int(n_dst*search_range) M = initial_matrix # Store indices of the nearest neighbor point of dst_pts to the converted point of src_pts nn_idx = [] converged = False for i in range(max_iter): nn_idx_tmp = [] dst_pts_list = [p for p in dst_pts] idx_list = list(range(0,dst_pts.shape[0])) first_pt = True for p in src_pts: # Convert source point with current conversion matrix p2 = M @ np.array([p[0], p[1], 1]) if first_pt: # First point should be searched in all destination points idx, _ = find_nearest_neighbor(dst_pts_list, p2) first_pt = False else: # Search nearest neighbor point in specified range around the last point n = int(min(n_search/2, len(idx_list)/2)) s = max(len(idx_list) + last_idx - n, 0) e = min(len(idx_list) + last_idx + n, 3*len(idx_list)) pts = (dst_pts_list + dst_pts_list + dst_pts_list)[s:e] idx, _ = find_nearest_neighbor(pts, p2) # The index acquired above is counted from 's', so actual index must be recovered idx = (idx + s) % len(idx_list) nn_idx_tmp += [idx_list[idx]] last_idx = idx del dst_pts_list[idx] del idx_list[idx] print('nn_idx: ', nn_idx_tmp) if nn_idx != [] and nn_idx == nn_idx_tmp: converged = True break dst_pts2 = np.zeros_like(src_pts) for j,idx in enumerate(nn_idx_tmp): dst_pts2[j,:] = dst_pts[idx,:] M = estimate_affine_2d(src_pts, dst_pts2) nn_idx = nn_idx_tmp #### Debug #### pts1 = [] pts2 = [] for p in src_pts: p1 = initial_matrix @ np.array([p[0], p[1], 1]) pts1 += [p1.astype('int')] p2 = M @ np.array([p[0], p[1], 1]) pts2 += [p2.astype('int')] plt.subplot(1,3,1), plt.imshow(create_pts_image(pts1)), plt.xticks([]), plt.yticks([]) plt.subplot(1,3,2), plt.imshow(create_pts_image(dst_pts)), plt.xticks([]), plt.yticks([]) plt.subplot(1,3,3), plt.imshow(create_pts_image(pts2)), plt.xticks([]), plt.yticks([]) plt.show() ############### return M, converged
変更処理試し
今まで使っていた画像の1つで試してみます。
ちなみに、上記の処理に追加しているデバッグ処理では、
- 最近傍点リストの全経過を表示
- 3つの輪郭点画像を表示
- テンプレート輪郭を初期変換行列で変換したもの
- 対象輪郭点
- テンプレート輪郭を最終の変換行列で変換したもの
ということをやっています。
img1 = cv2.imread('harupan_190428_1.jpg')
img = img1 templates = templates2019 # test_harupan_timeit(img, templates, svm) score, result_img = calc_harupan(img, templates, svm) print('Score: ', score) plt.figure(figsize=(6.4,4.8), dpi=200) plt.imshow(cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)), plt.xticks([]), plt.yticks([]) plt.show()
0 nn_idx: [104, 102, 99, 98, 95, 91, 90, 88, 67, 65, 64, 62, 53, 58, 59, 60, 57, 55, 54, 51, 49, 47, 46, 44, 42, 39, 36, 29, 28, 14, 15, 16, 87, 83, 81, 78, 77, 5, 6, 7, 3, 0, 105]
nn_idx: [103, 102, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 55, 54, 52, 50, 48, 46, 44, 42, 39, 40, 29, 26, 14, 15, 16, 87, 83, 82, 78, 77, 5, 6, 4, 3, 0, 105]
nn_idx: [103, 101, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 55, 54, 52, 50, 48, 46, 45, 42, 40, 41, 28, 26, 14, 15, 16, 87, 84, 82, 78, 77, 5, 6, 4, 3, 0, 104]
nn_idx: [103, 101, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 55, 54, 52, 50, 48, 47, 45, 43, 41, 40, 28, 26, 16, 15, 17, 88, 84, 82, 78, 77, 5, 6, 4, 3, 0, 104]
nn_idx: [103, 101, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 56, 54, 52, 50, 49, 47, 45, 43, 41, 40, 28, 25, 16, 15, 17, 88, 84, 82, 78, 77, 5, 6, 4, 3, 0, 104]
nn_idx: [103, 101, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 56, 54, 52, 50, 49, 47, 45, 43, 41, 40, 27, 25, 16, 15, 17, 88, 84, 82, 78, 77, 5, 6, 4, 3, 0, 104]
nn_idx: [103, 101, 99, 97, 95, 92, 90, 89, 67, 65, 64, 62, 53, 58, 59, 60, 57, 56, 54, 52, 50, 49, 47, 45, 43, 41, 40, 27, 25, 16, 15, 17, 88, 84, 82, 78, 77, 5, 6, 4, 3, 0, 104]

nn_idx: [102, 100, 98, 96, 92, 90, 89, 68, 67, 65, 62, 60, 58, 55, 51, 49, 48, 46, 43, 40, 35, 33, 32, 31, 29, 26, 25, 23, 20, 18, 15, 14, 13, 16, 87, 83, 80, 78, 4, 5, 3, 1, 103]
nn_idx: [102, 100, 98, 96, 92, 90, 89, 68, 67, 65, 62, 60, 58, 55, 51, 49, 47, 45, 44, 41, 36, 34, 32, 31, 29, 26, 25, 23, 21, 18, 16, 14, 13, 15, 87, 83, 79, 78, 4, 5, 3, 1, 105]
nn_idx: [102, 100, 98, 96, 92, 90, 89, 68, 67, 65, 62, 60, 58, 54, 51, 49, 47, 45, 44, 41, 36, 34, 32, 31, 29, 26, 25, 23, 21, 19, 16, 14, 13, 15, 87, 83, 79, 78, 5, 6, 3, 1, 105]
nn_idx: [102, 100, 98, 96, 92, 90, 89, 68, 67, 65, 62, 60, 58, 54, 51, 49, 47, 45, 44, 41, 36, 34, 33, 32, 29, 26, 25, 24, 21, 19, 16, 14, 13, 15, 87, 83, 79, 78, 5, 6, 4, 1, 105]
nn_idx: [102, 100, 98, 96, 92, 90, 89, 68, 67, 65, 62, 60, 58, 54, 51, 49, 47, 45, 44, 41, 36, 34, 33, 32, 29, 26, 25, 24, 21, 19, 16, 14, 13, 15, 87, 83, 79, 78, 5, 6, 4, 1, 105]

nn_idx: [0, 105, 101, 97, 94, 85, 83, 78, 74, 69, 65, 61, 56, 51, 47, 44, 39, 35, 31, 26, 23, 16, 12, 9, 8, 6, 3]
nn_idx: [0, 104, 101, 96, 92, 86, 83, 78, 74, 69, 65, 61, 56, 50, 47, 44, 41, 35, 30, 26, 23, 16, 12, 9, 8, 5, 1]
nn_idx: [0, 103, 100, 96, 92, 86, 83, 78, 74, 69, 65, 61, 55, 50, 47, 44, 41, 35, 30, 26, 23, 17, 14, 9, 8, 5, 1]
nn_idx: [0, 103, 99, 96, 91, 86, 83, 77, 74, 69, 65, 61, 55, 50, 47, 44, 41, 35, 30, 26, 23, 17, 14, 10, 8, 4, 1]
nn_idx: [106, 103, 99, 96, 91, 86, 83, 77, 73, 69, 65, 61, 55, 50, 47, 44, 41, 35, 29, 25, 23, 17, 14, 10, 8, 4, 1]
nn_idx: [106, 103, 99, 96, 91, 86, 83, 77, 73, 69, 65, 61, 55, 50, 47, 44, 41, 35, 29, 25, 23, 17, 14, 10, 8, 4, 1]

[0.5932692307692308, 0.762987012987013, 0.6706689536878216, 0.7790697674418605, 0.8884848484848484]
1 nn_idx: [98, 97, 94, 92, 90, 86, 84, 66, 65, 63, 61, 58, 51, 54, 56, 57, 55, 53, 52, 50, 49, 48, 45, 44, 42, 39, 40, 31, 29, 18, 19, 17, 20, 67, 77, 74, 73, 6, 8, 7, 5, 2, 99]
nn_idx: [98, 96, 94, 92, 90, 85, 84, 66, 65, 63, 61, 58, 51, 54, 56, 57, 55, 53, 52, 50, 49, 48, 45, 44, 42, 41, 40, 31, 29, 19, 18, 17, 20, 67, 77, 74, 73, 6, 8, 7, 5, 2, 99]
nn_idx: [98, 96, 94, 92, 90, 85, 84, 66, 65, 63, 61, 58, 51, 54, 56, 57, 55, 53, 52, 50, 49, 48, 46, 44, 42, 41, 40, 31, 29, 19, 18, 20, 67, 70, 77, 73, 72, 6, 8, 7, 5, 2, 99]
nn_idx: [98, 96, 94, 92, 90, 85, 84, 66, 65, 63, 61, 58, 51, 54, 56, 57, 55, 53, 52, 50, 49, 48, 46, 44, 42, 41, 40, 31, 29, 19, 18, 20, 67, 70, 77, 73, 72, 6, 8, 7, 5, 2, 99]
nn_idx: [97, 94, 92, 90, 87, 84, 85, 66, 65, 63, 60, 58, 56, 55, 52, 50, 48, 45, 44, 41, 36, 34, 35, 32, 31, 29, 27, 24, 23, 21, 19, 18, 17, 67, 80, 79, 76, 74, 6, 7, 4, 2, 98]
nn_idx: [97, 94, 92, 90, 87, 85, 84, 66, 65, 63, 61, 59, 56, 55, 52, 50, 48, 45, 44, 41, 38, 35, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 79, 78, 76, 74, 6, 7, 5, 2, 98]
nn_idx: [97, 94, 92, 90, 87, 85, 84, 66, 65, 63, 61, 59, 56, 55, 52, 50, 48, 45, 44, 41, 38, 36, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 79, 78, 75, 74, 6, 7, 5, 2, 99]
nn_idx: [97, 95, 92, 90, 87, 85, 84, 66, 65, 63, 61, 59, 56, 55, 52, 50, 48, 45, 44, 41, 38, 36, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 79, 78, 75, 74, 6, 7, 5, 3, 99]
nn_idx: [97, 95, 92, 91, 87, 85, 84, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 45, 44, 41, 38, 36, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 70, 78, 75, 74, 6, 7, 5, 3, 99]
nn_idx: [97, 95, 93, 91, 87, 85, 84, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 45, 44, 41, 38, 36, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 70, 78, 75, 74, 6, 7, 5, 3, 99]
nn_idx: [97, 95, 93, 91, 87, 85, 84, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 45, 44, 41, 38, 36, 34, 32, 31, 29, 27, 25, 23, 21, 19, 18, 17, 67, 70, 78, 75, 74, 6, 7, 5, 3, 99]

nn_idx: [1, 99, 95, 91, 87, 81, 77, 74, 70, 66, 63, 59, 55, 51, 47, 44, 41, 37, 33, 29, 25, 19, 16, 11, 9, 7, 3]
nn_idx: [1, 99, 95, 91, 86, 81, 79, 73, 70, 66, 63, 59, 55, 51, 47, 44, 41, 37, 32, 29, 25, 19, 16, 11, 9, 7, 3]
nn_idx: [1, 98, 95, 91, 86, 81, 79, 73, 70, 66, 63, 59, 55, 51, 47, 44, 41, 37, 32, 29, 25, 19, 16, 11, 9, 6, 3]
nn_idx: [1, 98, 94, 91, 86, 82, 79, 73, 69, 66, 63, 59, 55, 51, 47, 44, 41, 37, 32, 29, 25, 19, 16, 11, 9, 6, 3]
nn_idx: [1, 98, 94, 90, 86, 82, 79, 73, 69, 66, 63, 59, 55, 51, 47, 44, 41, 37, 32, 29, 25, 19, 16, 11, 9, 6, 3]
nn_idx: [1, 98, 94, 90, 86, 82, 79, 73, 69, 66, 63, 59, 55, 51, 47, 44, 41, 37, 32, 29, 25, 19, 16, 11, 9, 6, 3]
[0.5177884615384616, 0.7431761786600497, 0.6312178387650086, 0.7769933554817275, 0.8715151515151516]
2 nn_idx: [1, 99, 96, 93, 90, 86, 82, 78, 75, 71, 67, 64, 60, 55, 52, 49, 45, 42, 38, 35, 30, 27, 23, 19, 15, 10, 7, 5, 2]
nn_idx: [1, 99, 96, 93, 90, 86, 82, 78, 75, 71, 67, 64, 60, 55, 52, 48, 45, 42, 38, 35, 30, 27, 23, 19, 15, 10, 8, 5, 2]
nn_idx: [1, 99, 96, 93, 90, 86, 82, 78, 75, 71, 67, 64, 60, 55, 52, 48, 45, 42, 38, 35, 30, 27, 23, 19, 15, 10, 8, 5, 2]

[0.7173076923076923, 0.927257525083612, 0.7626208378088077, 0.7422126745435016, 0.7035445757250269]
3 nn_idx: [95, 94, 91, 90, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 48, 47, 45, 43, 41, 39, 38, 32, 29, 17, 19, 18, 65, 81, 79, 72, 73, 74, 6, 5, 3, 99, 96]
nn_idx: [96, 94, 92, 90, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 48, 47, 44, 43, 41, 40, 38, 31, 29, 17, 19, 18, 65, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 45, 43, 41, 40, 38, 31, 29, 17, 19, 18, 65, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 45, 43, 42, 40, 38, 31, 29, 17, 19, 18, 65, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 45, 43, 42, 40, 32, 31, 29, 17, 19, 18, 65, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 40, 31, 32, 29, 19, 18, 20, 67, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 48, 46, 44, 42, 40, 31, 30, 29, 19, 18, 20, 67, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 48, 46, 44, 43, 40, 31, 30, 29, 19, 18, 20, 67, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 48, 46, 44, 43, 40, 31, 30, 29, 19, 20, 18, 67, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [96, 94, 92, 91, 87, 86, 84, 66, 64, 63, 61, 59, 53, 54, 56, 57, 55, 52, 51, 50, 49, 48, 46, 44, 43, 40, 31, 30, 29, 19, 20, 18, 67, 81, 79, 72, 73, 74, 6, 5, 3, 99, 97]
nn_idx: [94, 92, 90, 88, 86, 84, 66, 64, 65, 62, 59, 57, 55, 54, 51, 49, 47, 45, 43, 40, 36, 34, 11, 12, 15, 29, 27, 25, 23, 22, 19, 18, 17, 20, 85, 80, 78, 72, 75, 5, 3, 99, 96]
nn_idx: [95, 92, 91, 87, 86, 84, 66, 64, 65, 62, 59, 57, 55, 52, 51, 48, 47, 45, 43, 40, 33, 34, 11, 12, 15, 29, 27, 25, 23, 21, 19, 18, 17, 20, 85, 80, 78, 74, 75, 5, 2, 99, 96]
nn_idx: [95, 92, 91, 89, 86, 84, 66, 65, 64, 61, 59, 56, 55, 52, 51, 48, 47, 45, 43, 31, 33, 34, 11, 12, 15, 29, 27, 25, 23, 21, 19, 18, 17, 20, 85, 79, 78, 75, 74, 5, 2, 99, 96]
nn_idx: [95, 93, 91, 89, 85, 84, 66, 65, 64, 61, 59, 56, 55, 52, 51, 49, 47, 45, 44, 31, 33, 34, 11, 12, 15, 29, 27, 25, 23, 21, 19, 18, 17, 20, 86, 79, 78, 75, 74, 3, 2, 99, 96]
nn_idx: [95, 93, 91, 90, 85, 84, 66, 65, 64, 61, 59, 56, 55, 52, 51, 49, 47, 45, 44, 31, 33, 34, 11, 12, 15, 29, 27, 25, 23, 21, 19, 18, 17, 20, 86, 79, 78, 75, 74, 3, 2, 99, 96]
nn_idx: [95, 93, 91, 90, 85, 84, 66, 65, 64, 61, 59, 56, 55, 52, 51, 49, 47, 45, 44, 31, 33, 34, 11, 12, 15, 29, 27, 25, 23, 21, 19, 18, 17, 20, 86, 79, 78, 75, 74, 3, 2, 99, 96]

nn_idx: [100, 97, 94, 89, 86, 83, 79, 72, 69, 66, 62, 58, 55, 51, 47, 43, 40, 36, 33, 29, 25, 19, 15, 12, 8, 4, 1]
nn_idx: [100, 97, 94, 89, 86, 83, 79, 72, 70, 66, 62, 58, 55, 51, 47, 43, 40, 36, 33, 29, 25, 19, 15, 12, 8, 5, 1]
nn_idx: [100, 97, 94, 89, 86, 83, 79, 72, 70, 66, 62, 58, 55, 50, 47, 43, 40, 36, 33, 29, 25, 19, 15, 12, 8, 5, 1]
nn_idx: [100, 97, 94, 89, 86, 83, 79, 72, 70, 66, 62, 58, 55, 50, 47, 43, 40, 36, 33, 29, 25, 19, 15, 12, 8, 5, 1]
[0.5129807692307693, 0.7327188940092166, 0.6183533447684391, 0.6362126245847176, 0.8739393939393939]
4 nn_idx: [4, 2, 0, 97, 95, 92, 91, 89, 86, 84, 81, 79, 77, 73, 71, 69, 67, 65, 62, 60, 57, 55, 53, 51, 49, 47, 44, 41, 39, 37, 34, 31, 29, 26, 24, 21, 20, 18, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 88, 86, 84, 81, 79, 77, 73, 71, 69, 67, 65, 62, 60, 58, 55, 53, 51, 49, 47, 44, 41, 39, 37, 34, 31, 29, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 88, 86, 84, 81, 79, 77, 73, 71, 69, 67, 65, 62, 60, 58, 56, 53, 51, 49, 47, 44, 41, 39, 37, 34, 31, 29, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 88, 86, 84, 81, 79, 77, 73, 71, 69, 67, 65, 62, 60, 58, 56, 53, 51, 49, 47, 44, 41, 39, 37, 34, 31, 29, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]

nn_idx: [2, 0, 98, 95, 93, 91, 89, 87, 85, 83, 82, 69, 68, 66, 60, 58, 56, 53, 51, 43, 44, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 29, 27, 25, 23, 21, 17, 15, 9, 7, 4]
nn_idx: [2, 0, 98, 95, 93, 91, 89, 87, 85, 83, 82, 69, 68, 66, 61, 59, 56, 55, 52, 50, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 85, 83, 82, 69, 68, 66, 61, 59, 57, 55, 53, 51, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 91, 89, 87, 85, 83, 82, 69, 68, 66, 61, 59, 58, 56, 53, 51, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 17, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 87, 85, 83, 82, 69, 68, 66, 62, 59, 58, 56, 53, 51, 43, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 17, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 87, 85, 83, 82, 69, 68, 66, 62, 60, 58, 56, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 17, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 87, 85, 83, 82, 69, 68, 66, 62, 60, 58, 56, 54, 52, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 17, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 87, 85, 83, 82, 69, 68, 66, 62, 60, 58, 56, 54, 52, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 31, 30, 27, 26, 23, 20, 19, 17, 9, 7, 4]

[0.60625, 0.7112299465240641, 0.9240994854202401, 0.7333887043189369, 0.6907308377896613]
5 nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 66, 62, 58, 54, 51, 50, 46, 43, 37, 34, 30, 27, 23, 20, 16, 14, 8, 5, 2]
nn_idx: [1, 97, 93, 90, 87, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 45, 42, 37, 34, 30, 27, 23, 20, 16, 11, 8, 5, 2]
nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 45, 41, 37, 33, 30, 27, 23, 20, 16, 11, 8, 5, 2]
nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 44, 41, 37, 33, 30, 26, 23, 20, 16, 11, 8, 5, 2]
nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 44, 41, 37, 33, 30, 26, 23, 19, 16, 11, 8, 5, 2]
nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 44, 41, 37, 33, 30, 26, 23, 19, 16, 11, 8, 4, 2]
nn_idx: [1, 97, 93, 90, 86, 83, 80, 76, 73, 69, 65, 62, 58, 54, 51, 48, 44, 41, 37, 33, 30, 26, 23, 19, 16, 11, 8, 4, 2]

[0.66875, 0.9297658862876255, 0.7671614100185529, 0.7374768089053803, 0.7476808905380334]
6 nn_idx: [4, 2, 0, 98, 95, 93, 91, 89, 87, 85, 82, 80, 77, 74, 72, 70, 68, 65, 63, 61, 59, 56, 54, 52, 49, 47, 44, 42, 39, 37, 33, 31, 28, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 89, 87, 85, 82, 80, 77, 74, 72, 70, 67, 65, 63, 61, 59, 56, 54, 52, 49, 47, 44, 42, 39, 37, 33, 31, 28, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 89, 87, 85, 81, 79, 77, 74, 72, 70, 67, 65, 63, 61, 59, 56, 54, 52, 49, 47, 44, 42, 39, 37, 33, 31, 28, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 89, 87, 84, 81, 79, 77, 74, 72, 70, 67, 65, 63, 61, 58, 56, 54, 52, 49, 47, 44, 42, 39, 37, 33, 31, 28, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 91, 89, 87, 84, 81, 79, 77, 74, 72, 70, 67, 65, 63, 61, 58, 56, 54, 52, 49, 47, 44, 42, 39, 37, 33, 31, 28, 26, 24, 21, 19, 17, 15, 12, 10, 7, 5]

nn_idx: [2, 0, 98, 96, 94, 92, 90, 88, 85, 84, 83, 70, 69, 66, 61, 59, 57, 55, 52, 50, 43, 42, 41, 40, 38, 39, 37, 77, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 15, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 88, 85, 84, 83, 70, 69, 66, 62, 60, 58, 55, 53, 51, 43, 42, 41, 40, 38, 39, 76, 77, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 94, 92, 90, 88, 85, 84, 83, 69, 70, 66, 62, 60, 58, 56, 54, 52, 43, 42, 41, 40, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [2, 1, 98, 96, 94, 92, 90, 88, 85, 84, 83, 69, 68, 66, 62, 60, 58, 56, 55, 52, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [3, 1, 99, 96, 94, 92, 90, 88, 85, 84, 83, 69, 68, 66, 62, 60, 58, 56, 55, 52, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 88, 85, 84, 83, 69, 68, 66, 63, 61, 58, 56, 55, 52, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 88, 85, 84, 83, 69, 68, 66, 63, 61, 59, 57, 55, 52, 43, 42, 41, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 88, 85, 84, 83, 69, 68, 66, 63, 61, 59, 57, 55, 53, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 5]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 87, 85, 84, 83, 69, 68, 66, 63, 61, 59, 58, 55, 53, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 5]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 87, 85, 84, 83, 69, 68, 66, 63, 61, 60, 58, 55, 53, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 5]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 87, 85, 84, 83, 69, 68, 66, 63, 61, 60, 58, 55, 53, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 25, 23, 20, 18, 16, 9, 7, 5]

nn_idx: [67, 62, 58, 53, 50, 40, 37, 35, 38, 39, 14, 13, 8, 4, 1, 97, 94, 91, 90, 23, 22, 33, 31, 29, 30, 66, 68]
nn_idx: [66, 61, 57, 53, 42, 40, 37, 35, 38, 39, 14, 12, 8, 5, 1, 98, 95, 92, 91, 24, 21, 19, 31, 30, 32, 67, 68]
nn_idx: [62, 60, 57, 53, 42, 40, 37, 35, 38, 39, 14, 12, 8, 5, 2, 99, 95, 92, 91, 24, 22, 19, 31, 30, 32, 67, 68]
nn_idx: [62, 60, 57, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 5, 2, 99, 96, 92, 91, 24, 22, 19, 32, 30, 31, 67, 72]
nn_idx: [62, 59, 56, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 4, 2, 99, 96, 93, 25, 26, 22, 19, 32, 30, 31, 67, 72]
nn_idx: [61, 59, 56, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 4, 2, 99, 96, 93, 25, 24, 22, 19, 32, 30, 31, 67, 73]
nn_idx: [61, 59, 56, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 4, 2, 0, 97, 93, 25, 24, 22, 19, 32, 30, 31, 67, 73]
nn_idx: [61, 59, 56, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 4, 2, 0, 97, 94, 26, 25, 22, 19, 32, 30, 31, 67, 73]
nn_idx: [61, 59, 56, 53, 42, 40, 38, 36, 37, 39, 14, 11, 7, 4, 2, 0, 97, 94, 26, 25, 22, 19, 32, 30, 31, 67, 73]

[0.6120192307692307, 0.7450900163666121, 0.9236706689536878, 0.7408637873754154, 0.7175757575757575]
7 nn_idx: [1, 98, 95, 91, 87, 83, 80, 77, 73, 70, 66, 63, 59, 55, 52, 49, 45, 42, 37, 34, 31, 27, 24, 20, 17, 11, 8, 5, 2]
nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 66, 63, 59, 55, 52, 49, 45, 42, 38, 34, 31, 27, 24, 20, 17, 11, 8, 4, 2]
nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 66, 63, 59, 55, 52, 49, 45, 42, 38, 34, 31, 27, 24, 20, 17, 11, 8, 4, 2]

[0.6572115384615385, 0.9264214046822743, 0.7938504542278128, 0.7693920335429769, 0.737246680642907]
8 nn_idx: [1, 99, 95, 91, 88, 85, 81, 77, 73, 71, 67, 64, 60, 56, 53, 47, 44, 41, 37, 34, 29, 26, 23, 19, 16, 11, 7, 5, 2]
nn_idx: [1, 98, 95, 92, 88, 85, 81, 77, 74, 71, 67, 64, 60, 56, 53, 47, 45, 41, 37, 33, 30, 26, 23, 19, 16, 11, 8, 5, 2]
nn_idx: [1, 98, 95, 92, 88, 85, 81, 77, 74, 71, 67, 64, 60, 56, 53, 48, 45, 41, 37, 33, 30, 26, 23, 19, 16, 11, 9, 5, 2]
nn_idx: [1, 98, 95, 92, 88, 85, 81, 78, 74, 71, 67, 64, 60, 56, 53, 48, 45, 41, 37, 33, 30, 26, 23, 19, 16, 11, 9, 5, 2]
nn_idx: [1, 98, 95, 92, 88, 85, 81, 78, 74, 71, 68, 64, 60, 56, 53, 48, 45, 41, 37, 33, 30, 26, 23, 19, 16, 11, 9, 5, 2]
nn_idx: [1, 98, 95, 92, 88, 85, 81, 78, 74, 71, 68, 64, 60, 56, 53, 48, 45, 41, 37, 33, 30, 26, 23, 19, 16, 11, 9, 5, 2]
[0.5634615384615385, 0.9439799331103679, 0.8263041065482797, 0.8079911209766926, 0.7896781354051055]
9 nn_idx: [97, 95, 93, 91, 89, 86, 85, 68, 66, 64, 60, 58, 53, 56, 57, 59, 55, 54, 52, 51, 50, 47, 46, 43, 42, 40, 38, 32, 30, 19, 20, 18, 65, 82, 80, 76, 75, 77, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 91, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 20, 18, 65, 71, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 20, 18, 17, 93, 80, 76, 74, 75, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 88, 86, 85, 68, 66, 64, 60, 58, 53, 54, 56, 57, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 93, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [97, 95, 94, 92, 89, 86, 85, 68, 66, 64, 60, 57, 53, 54, 56, 58, 55, 52, 51, 50, 49, 47, 46, 44, 42, 41, 38, 32, 30, 19, 18, 20, 17, 88, 80, 76, 75, 74, 8, 6, 4, 99, 98]
nn_idx: [95, 93, 91, 90, 87, 86, 85, 66, 65, 64, 61, 59, 57, 55, 52, 50, 47, 46, 44, 41, 36, 34, 11, 12, 32, 30, 28, 25, 23, 21, 19, 18, 17, 84, 71, 81, 79, 76, 77, 6, 4, 99, 97]
nn_idx: [96, 94, 92, 90, 88, 86, 85, 68, 67, 64, 60, 59, 57, 55, 52, 50, 47, 45, 44, 41, 36, 34, 11, 12, 14, 30, 28, 26, 23, 21, 19, 18, 17, 83, 71, 81, 78, 76, 77, 6, 3, 99, 98]
nn_idx: [96, 94, 92, 90, 88, 86, 85, 68, 67, 64, 60, 59, 57, 55, 52, 50, 47, 45, 44, 41, 36, 34, 11, 12, 14, 30, 28, 25, 23, 21, 19, 18, 17, 83, 71, 81, 78, 77, 76, 6, 3, 99, 98]
nn_idx: [96, 94, 92, 90, 88, 86, 85, 68, 67, 64, 60, 59, 57, 55, 52, 50, 47, 45, 44, 41, 36, 34, 11, 12, 14, 30, 28, 25, 23, 21, 19, 18, 17, 83, 71, 81, 78, 77, 76, 6, 3, 99, 98]
nn_idx: [1, 98, 95, 91, 87, 84, 80, 76, 71, 68, 64, 60, 56, 52, 47, 44, 41, 37, 33, 30, 25, 20, 16, 13, 9, 6, 2]
nn_idx: [1, 98, 95, 91, 87, 83, 80, 76, 71, 68, 64, 60, 56, 52, 47, 44, 41, 37, 33, 30, 25, 20, 16, 13, 9, 6, 2]
nn_idx: [1, 98, 95, 91, 87, 83, 80, 76, 71, 68, 64, 60, 56, 52, 47, 44, 41, 37, 33, 30, 25, 20, 16, 13, 9, 6, 2]
[0.5240384615384616, 0.7526881720430108, 0.6132075471698113, 0.6976744186046512, 0.8836363636363637]
10 nn_idx: [3, 1, 99, 97, 94, 92, 90, 88, 86, 84, 81, 79, 76, 73, 71, 69, 67, 65, 61, 59, 57, 55, 53, 51, 49, 46, 43, 41, 39, 36, 33, 31, 29, 26, 24, 21, 19, 17, 15, 12, 9, 6, 4]
nn_idx: [3, 1, 99, 97, 94, 92, 90, 88, 86, 84, 80, 79, 76, 73, 71, 69, 67, 64, 62, 59, 57, 55, 53, 51, 49, 45, 43, 41, 39, 36, 34, 31, 29, 26, 24, 21, 19, 17, 15, 12, 9, 6, 4]
nn_idx: [4, 2, 99, 97, 94, 92, 90, 88, 86, 83, 80, 79, 76, 73, 71, 69, 66, 64, 62, 59, 57, 55, 53, 51, 49, 45, 43, 41, 39, 36, 34, 32, 29, 26, 24, 21, 19, 17, 15, 12, 9, 6, 5]
nn_idx: [4, 2, 0, 97, 94, 92, 90, 88, 85, 83, 80, 79, 76, 73, 71, 69, 66, 64, 62, 59, 57, 55, 53, 51, 49, 45, 43, 41, 39, 37, 34, 32, 29, 26, 24, 21, 19, 17, 15, 12, 9, 7, 5]
nn_idx: [4, 2, 0, 97, 94, 92, 90, 88, 85, 83, 80, 79, 76, 73, 71, 69, 66, 64, 62, 59, 57, 55, 53, 51, 49, 45, 43, 41, 39, 37, 34, 32, 29, 26, 24, 21, 19, 17, 15, 12, 9, 7, 5]

nn_idx: [2, 99, 97, 95, 93, 91, 89, 87, 85, 83, 81, 69, 70, 66, 59, 57, 55, 53, 51, 43, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 30, 29, 27, 26, 23, 21, 17, 15, 9, 6, 4]
nn_idx: [1, 99, 97, 95, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 60, 58, 56, 54, 52, 50, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 29, 27, 26, 23, 20, 19, 16, 9, 6, 3]
nn_idx: [1, 99, 97, 95, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 52, 50, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 30, 27, 26, 23, 20, 19, 16, 9, 6, 3]
nn_idx: [1, 99, 97, 95, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 30, 27, 26, 23, 20, 19, 16, 9, 7, 3]
nn_idx: [2, 0, 98, 95, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 30, 27, 26, 23, 20, 19, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 30, 27, 26, 23, 20, 19, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 33, 32, 30, 27, 26, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 32, 30, 27, 26, 23, 20, 18, 16, 9, 7, 4]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 84, 83, 81, 69, 68, 66, 61, 59, 57, 55, 53, 51, 42, 41, 40, 39, 38, 37, 76, 75, 78, 79, 36, 34, 32, 30, 27, 26, 23, 20, 18, 16, 9, 7, 4]

[0.6173076923076923, 0.7100840336134453, 0.9275300171526587, 0.7346345514950166, 0.6834733893557423]
11 nn_idx: [1, 98, 95, 94, 91, 86, 83, 84, 65, 64, 63, 58, 51, 57, 56, 59, 55, 54, 53, 52, 50, 48, 46, 44, 42, 40, 37, 32, 30, 17, 18, 19, 20, 16, 2, 74, 73, 8, 9, 7, 6, 3, 0]
nn_idx: [99, 98, 95, 94, 91, 84, 83, 66, 65, 64, 63, 58, 51, 55, 57, 56, 54, 53, 52, 50, 49, 48, 46, 44, 42, 41, 37, 32, 30, 17, 19, 18, 20, 67, 75, 74, 73, 7, 9, 8, 6, 3, 1]
nn_idx: [99, 97, 95, 93, 90, 84, 83, 66, 65, 63, 60, 58, 51, 26, 24, 23, 50, 54, 53, 52, 49, 48, 46, 44, 42, 40, 37, 32, 30, 27, 19, 18, 67, 71, 75, 74, 73, 7, 9, 6, 5, 3, 1]
nn_idx: [98, 96, 94, 93, 91, 84, 83, 66, 65, 63, 61, 58, 51, 26, 24, 23, 50, 53, 52, 49, 48, 47, 45, 44, 42, 40, 37, 32, 30, 17, 19, 18, 20, 67, 75, 74, 73, 7, 9, 6, 5, 2, 99]
nn_idx: [98, 95, 94, 92, 90, 84, 83, 66, 65, 63, 60, 58, 51, 26, 24, 23, 50, 53, 52, 49, 48, 47, 45, 43, 41, 40, 37, 32, 30, 17, 18, 19, 20, 67, 76, 74, 73, 7, 8, 6, 5, 2, 97]
nn_idx: [97, 95, 94, 91, 90, 84, 83, 66, 65, 63, 60, 58, 51, 26, 24, 23, 50, 53, 52, 49, 48, 46, 45, 43, 41, 40, 37, 32, 30, 17, 19, 18, 20, 67, 78, 73, 74, 7, 8, 6, 5, 2, 98]
nn_idx: [97, 95, 93, 91, 90, 84, 83, 66, 65, 63, 60, 58, 51, 26, 24, 23, 50, 53, 52, 49, 48, 46, 45, 43, 41, 40, 37, 32, 30, 17, 19, 18, 20, 67, 78, 73, 74, 7, 8, 6, 5, 2, 98]
nn_idx: [97, 95, 93, 91, 90, 84, 83, 66, 65, 63, 60, 58, 51, 26, 24, 23, 50, 53, 52, 49, 48, 46, 45, 43, 41, 40, 37, 32, 30, 17, 19, 18, 20, 67, 78, 73, 74, 7, 8, 6, 5, 2, 98]
nn_idx: [98, 95, 94, 91, 89, 84, 83, 66, 65, 63, 61, 59, 57, 55, 53, 51, 49, 46, 44, 42, 37, 36, 34, 33, 32, 29, 27, 25, 23, 21, 19, 17, 16, 18, 67, 77, 74, 73, 7, 6, 5, 3, 1]
nn_idx: [98, 95, 93, 91, 89, 84, 83, 66, 65, 63, 61, 59, 57, 55, 53, 50, 49, 46, 44, 42, 37, 36, 34, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 1]
nn_idx: [97, 95, 93, 91, 89, 85, 83, 66, 65, 63, 61, 59, 57, 55, 53, 50, 49, 46, 44, 42, 37, 36, 34, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 1]
nn_idx: [97, 95, 93, 91, 87, 85, 83, 66, 65, 63, 61, 59, 57, 55, 53, 50, 49, 46, 44, 42, 37, 36, 35, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 1]
nn_idx: [97, 95, 93, 91, 87, 85, 83, 66, 65, 63, 61, 59, 57, 55, 53, 50, 48, 46, 44, 42, 37, 36, 35, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 2]
nn_idx: [97, 95, 93, 90, 87, 85, 83, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 46, 44, 42, 37, 36, 35, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 2]
nn_idx: [97, 95, 92, 90, 87, 85, 83, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 46, 44, 42, 37, 36, 35, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 2]
nn_idx: [97, 95, 92, 90, 87, 85, 83, 66, 65, 63, 61, 59, 57, 55, 52, 50, 48, 46, 44, 42, 37, 36, 35, 33, 32, 29, 27, 25, 23, 21, 19, 17, 18, 67, 70, 78, 74, 73, 7, 8, 6, 3, 2]

nn_idx: [3, 1, 97, 93, 90, 79, 75, 74, 71, 67, 64, 60, 56, 52, 48, 44, 41, 38, 33, 29, 26, 19, 15, 11, 10, 7, 4]
nn_idx: [3, 99, 96, 92, 90, 80, 75, 74, 71, 67, 64, 60, 55, 51, 48, 44, 41, 37, 32, 29, 25, 19, 17, 12, 10, 7, 4]
nn_idx: [2, 99, 95, 91, 90, 80, 78, 74, 71, 67, 64, 60, 55, 51, 48, 45, 41, 37, 32, 29, 25, 20, 17, 13, 10, 7, 3]
nn_idx: [1, 98, 95, 91, 90, 80, 78, 73, 70, 67, 64, 60, 55, 51, 48, 45, 41, 37, 32, 29, 25, 20, 17, 13, 10, 6, 3]
nn_idx: [1, 98, 95, 91, 89, 81, 78, 73, 70, 67, 64, 60, 55, 51, 48, 45, 41, 37, 32, 29, 25, 20, 17, 13, 10, 6, 3]
nn_idx: [1, 98, 95, 91, 89, 81, 78, 73, 70, 67, 64, 60, 55, 51, 48, 45, 41, 37, 32, 29, 25, 20, 17, 13, 10, 6, 3]
[0.5384615384615384, 0.7194444444444444, 0.6286449399656947, 0.787375415282392, 0.8606060606060606]
12 nn_idx: [1, 95, 93, 91, 89, 87, 84, 82, 80, 77, 74, 73, 71, 67, 65, 64, 62, 60, 57, 54, 53, 50, 48, 46, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 13, 10, 7, 5, 4, 2]
nn_idx: [1, 96, 93, 91, 89, 87, 84, 82, 80, 77, 74, 73, 71, 67, 65, 64, 62, 59, 57, 54, 53, 50, 48, 45, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 12, 10, 8, 5, 4, 2]
nn_idx: [1, 96, 93, 91, 89, 87, 84, 82, 80, 77, 74, 73, 71, 67, 65, 64, 62, 59, 57, 54, 52, 50, 48, 45, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 12, 10, 8, 5, 4, 2]
nn_idx: [1, 96, 93, 91, 89, 86, 84, 82, 80, 77, 74, 73, 71, 67, 65, 64, 62, 59, 57, 54, 52, 50, 48, 45, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 12, 10, 8, 5, 4, 2]
nn_idx: [1, 96, 93, 91, 89, 86, 84, 82, 79, 77, 74, 73, 71, 67, 65, 64, 62, 59, 57, 54, 52, 50, 48, 45, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 12, 10, 8, 5, 4, 2]
nn_idx: [1, 96, 93, 91, 89, 86, 84, 82, 79, 77, 74, 73, 71, 67, 65, 64, 62, 59, 57, 54, 52, 50, 48, 45, 43, 41, 38, 36, 34, 32, 29, 27, 24, 22, 19, 16, 14, 12, 10, 8, 5, 4, 2]

nn_idx: [96, 93, 91, 89, 87, 85, 83, 80, 78, 76, 75, 64, 63, 62, 55, 53, 50, 48, 46, 38, 37, 36, 35, 34, 33, 32, 70, 71, 72, 73, 31, 29, 27, 24, 22, 20, 18, 16, 13, 10, 5, 4, 1]
nn_idx: [96, 93, 91, 89, 87, 85, 83, 80, 78, 76, 75, 64, 63, 61, 55, 54, 51, 49, 47, 44, 37, 36, 35, 34, 33, 32, 70, 71, 72, 73, 31, 29, 27, 25, 23, 21, 18, 15, 13, 11, 5, 3, 1]
nn_idx: [95, 93, 91, 89, 87, 85, 83, 80, 78, 76, 75, 64, 63, 61, 56, 54, 52, 50, 47, 45, 37, 36, 35, 34, 33, 32, 70, 69, 72, 73, 31, 29, 27, 25, 23, 21, 18, 15, 14, 12, 5, 3, 1]
nn_idx: [95, 93, 91, 89, 87, 85, 83, 80, 78, 76, 75, 63, 62, 61, 56, 54, 52, 50, 48, 46, 37, 36, 35, 34, 33, 32, 70, 69, 72, 73, 31, 29, 27, 25, 23, 21, 19, 15, 14, 12, 5, 3, 1]
nn_idx: [95, 93, 91, 89, 87, 85, 83, 80, 78, 76, 75, 63, 62, 61, 56, 54, 52, 50, 48, 46, 37, 36, 35, 34, 33, 32, 70, 69, 72, 73, 31, 29, 27, 25, 23, 21, 19, 15, 14, 12, 5, 3, 1]

nn_idx: [61, 55, 52, 47, 37, 34, 32, 29, 33, 35, 9, 8, 4, 1, 93, 90, 87, 84, 83, 18, 17, 27, 26, 25, 28, 62, 63]
nn_idx: [56, 54, 51, 47, 36, 34, 32, 31, 33, 35, 9, 7, 4, 1, 94, 91, 88, 85, 83, 18, 17, 14, 27, 25, 26, 61, 62]
nn_idx: [56, 54, 50, 46, 37, 34, 32, 31, 33, 35, 9, 7, 4, 1, 95, 91, 89, 85, 83, 18, 17, 14, 27, 26, 28, 62, 64]
nn_idx: [56, 53, 50, 46, 37, 34, 32, 31, 33, 35, 9, 7, 4, 1, 95, 92, 89, 85, 83, 18, 17, 14, 27, 26, 28, 62, 66]
nn_idx: [55, 53, 50, 46, 37, 35, 33, 31, 32, 34, 9, 7, 4, 1, 95, 92, 89, 86, 20, 21, 17, 14, 27, 26, 28, 62, 66]
nn_idx: [55, 53, 50, 46, 37, 34, 33, 31, 32, 35, 9, 7, 4, 1, 95, 92, 90, 86, 20, 21, 17, 14, 27, 26, 28, 62, 67]
nn_idx: [55, 53, 50, 46, 37, 34, 33, 31, 32, 35, 9, 7, 4, 1, 95, 92, 90, 86, 20, 21, 17, 14, 27, 26, 28, 62, 67]

[0.5576923076923077, 0.7215932914046121, 0.9292452830188679, 0.7350498338870433, 0.7321212121212122]
13 nn_idx: [5, 3, 2, 0, 96, 95, 93, 73, 72, 71, 70, 67, 60, 63, 64, 65, 62, 61, 59, 58, 57, 56, 54, 52, 50, 49, 48, 41, 39, 27, 29, 30, 76, 89, 88, 80, 82, 83, 17, 16, 13, 9, 6]
nn_idx: [5, 3, 2, 0, 96, 94, 93, 73, 72, 71, 70, 67, 60, 63, 64, 65, 62, 61, 59, 58, 57, 56, 54, 52, 50, 49, 48, 41, 40, 27, 29, 30, 76, 89, 88, 80, 82, 83, 17, 16, 13, 9, 6]
nn_idx: [5, 4, 2, 0, 96, 94, 93, 73, 72, 71, 70, 67, 60, 63, 64, 65, 62, 61, 59, 58, 57, 56, 54, 52, 50, 49, 48, 41, 40, 27, 29, 30, 76, 89, 88, 80, 82, 83, 17, 16, 13, 9, 6]
nn_idx: [5, 4, 2, 0, 96, 94, 93, 73, 72, 71, 70, 67, 60, 63, 64, 65, 62, 61, 59, 58, 57, 56, 54, 52, 50, 49, 48, 41, 40, 27, 29, 30, 76, 89, 88, 80, 82, 83, 17, 16, 13, 9, 6]
nn_idx: [4, 2, 0, 97, 95, 93, 74, 73, 72, 70, 68, 65, 64, 62, 59, 58, 56, 54, 52, 50, 43, 44, 21, 22, 23, 37, 36, 35, 33, 31, 30, 28, 29, 75, 77, 89, 87, 82, 83, 15, 13, 7, 5]
nn_idx: [4, 2, 0, 96, 95, 93, 74, 73, 72, 70, 67, 65, 64, 62, 59, 58, 56, 55, 52, 50, 43, 44, 21, 22, 23, 37, 36, 35, 33, 31, 29, 28, 27, 30, 75, 89, 86, 82, 83, 15, 13, 8, 6]
nn_idx: [5, 2, 1, 96, 94, 93, 74, 73, 72, 70, 67, 65, 64, 62, 59, 58, 56, 55, 52, 48, 43, 44, 21, 22, 23, 37, 36, 35, 33, 31, 29, 28, 27, 30, 75, 89, 86, 83, 84, 15, 13, 9, 6]
nn_idx: [5, 3, 1, 96, 94, 93, 73, 72, 71, 70, 67, 65, 64, 62, 59, 58, 56, 55, 52, 42, 45, 44, 21, 22, 23, 39, 37, 35, 33, 31, 29, 28, 27, 74, 78, 89, 86, 83, 84, 15, 13, 9, 7]
nn_idx: [5, 3, 1, 96, 94, 93, 73, 72, 71, 70, 67, 65, 64, 62, 59, 58, 56, 55, 52, 42, 44, 45, 21, 22, 23, 39, 37, 35, 33, 31, 29, 28, 27, 74, 78, 89, 86, 83, 84, 14, 13, 9, 7]
nn_idx: [5, 3, 1, 96, 94, 93, 73, 72, 71, 70, 67, 65, 64, 62, 59, 58, 56, 55, 52, 42, 44, 45, 21, 22, 23, 39, 37, 35, 33, 31, 29, 28, 27, 74, 78, 89, 86, 83, 84, 14, 13, 9, 7]
nn_idx: [10, 7, 3, 98, 95, 91, 88, 82, 78, 74, 71, 67, 62, 59, 56, 52, 49, 46, 42, 39, 34, 30, 26, 22, 19, 15, 11]
nn_idx: [10, 7, 3, 98, 95, 91, 88, 82, 78, 74, 71, 67, 62, 59, 56, 52, 49, 46, 43, 39, 34, 30, 26, 22, 19, 15, 11]
nn_idx: [10, 7, 3, 98, 95, 91, 88, 82, 78, 74, 71, 67, 62, 59, 56, 52, 49, 46, 43, 39, 34, 30, 26, 22, 19, 15, 11]
[0.5836538461538461, 0.7120098039215687, 0.6016295025728988, 0.6536544850498338, 0.8775757575757576]
14 nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 67, 63, 59, 55, 52, 47, 43, 40, 37, 33, 30, 26, 22, 19, 15, 12, 8, 4, 2]
nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 66, 63, 59, 55, 52, 47, 44, 40, 37, 33, 30, 26, 22, 19, 15, 12, 9, 4, 2]
nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 66, 63, 59, 55, 52, 47, 44, 41, 37, 33, 30, 26, 22, 19, 15, 12, 9, 4, 2]
nn_idx: [1, 98, 95, 91, 88, 84, 80, 77, 73, 70, 66, 63, 59, 55, 52, 47, 44, 41, 37, 33, 30, 26, 22, 19, 15, 12, 9, 4, 2]

[0.6995192307692308, 0.9423076923076923, 0.7399829497016197, 0.7152600170502984, 0.6871270247229326]
15 nn_idx: [2, 0, 98, 96, 93, 91, 89, 87, 84, 82, 79, 77, 75, 72, 69, 67, 65, 63, 60, 58, 56, 53, 51, 48, 46, 44, 40, 38, 36, 34, 31, 29, 26, 24, 22, 19, 17, 15, 13, 10, 8, 5, 3]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 86, 84, 82, 79, 77, 75, 72, 69, 67, 65, 63, 60, 58, 56, 53, 51, 48, 46, 44, 40, 38, 36, 34, 31, 29, 26, 24, 22, 19, 17, 15, 13, 10, 8, 5, 3]
nn_idx: [2, 0, 98, 96, 93, 91, 89, 86, 84, 82, 79, 77, 75, 72, 69, 67, 65, 63, 60, 58, 56, 53, 51, 48, 46, 44, 40, 38, 36, 34, 31, 29, 26, 24, 22, 19, 17, 15, 13, 10, 8, 5, 3]

nn_idx: [0, 98, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 68, 64, 58, 56, 54, 51, 49, 46, 40, 39, 38, 36, 35, 34, 37, 74, 76, 77, 75, 33, 18, 27, 24, 23, 20, 19, 15, 13, 7, 5, 3]
nn_idx: [1, 98, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 68, 64, 59, 56, 54, 53, 49, 47, 40, 39, 38, 37, 36, 35, 74, 75, 76, 77, 34, 31, 29, 27, 25, 23, 20, 18, 16, 13, 8, 5, 3]
nn_idx: [1, 98, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 59, 57, 55, 53, 50, 48, 40, 39, 38, 37, 36, 35, 74, 73, 76, 77, 34, 31, 29, 27, 25, 23, 20, 18, 16, 13, 8, 6, 3]
nn_idx: [1, 98, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 55, 53, 51, 48, 40, 39, 38, 37, 35, 36, 74, 73, 76, 77, 34, 31, 29, 28, 25, 23, 20, 18, 16, 13, 8, 6, 3]
nn_idx: [1, 99, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 55, 53, 51, 48, 40, 39, 38, 37, 35, 34, 73, 74, 76, 77, 75, 33, 29, 28, 25, 23, 20, 18, 16, 13, 8, 6, 3]
nn_idx: [1, 99, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 56, 53, 51, 49, 40, 39, 38, 37, 35, 34, 73, 74, 76, 77, 75, 33, 29, 28, 25, 23, 20, 18, 16, 13, 8, 6, 3]
nn_idx: [1, 99, 96, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 56, 54, 51, 49, 40, 39, 38, 36, 35, 34, 73, 74, 76, 77, 75, 33, 29, 28, 25, 23, 20, 18, 16, 13, 8, 6, 3]
nn_idx: [1, 99, 97, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 56, 54, 52, 49, 39, 38, 37, 36, 35, 34, 73, 74, 76, 77, 75, 33, 29, 28, 25, 23, 20, 18, 16, 14, 8, 6, 3]
nn_idx: [1, 99, 97, 94, 92, 90, 87, 85, 82, 81, 80, 67, 66, 64, 60, 58, 56, 54, 52, 49, 39, 38, 37, 36, 35, 34, 73, 74, 76, 77, 75, 33, 29, 28, 25, 23, 20, 18, 16, 14, 8, 6, 3]

nn_idx: [64, 59, 55, 49, 40, 37, 34, 32, 35, 36, 12, 11, 6, 3, 98, 95, 92, 89, 88, 21, 20, 17, 29, 27, 28, 63, 66]
nn_idx: [61, 57, 54, 49, 39, 37, 35, 32, 34, 36, 12, 10, 6, 3, 99, 96, 93, 90, 89, 22, 20, 17, 29, 28, 30, 65, 68]
nn_idx: [60, 57, 54, 49, 39, 37, 35, 32, 34, 36, 12, 9, 6, 3, 99, 96, 93, 90, 91, 23, 20, 17, 29, 28, 30, 65, 69]
nn_idx: [59, 57, 53, 49, 39, 37, 35, 32, 34, 36, 12, 9, 5, 2, 99, 96, 93, 91, 23, 24, 20, 17, 29, 28, 30, 65, 70]
nn_idx: [59, 56, 53, 49, 39, 37, 35, 33, 34, 36, 12, 9, 5, 2, 99, 96, 94, 91, 23, 24, 20, 17, 29, 28, 30, 65, 71]
nn_idx: [58, 56, 53, 49, 39, 37, 35, 33, 34, 36, 12, 9, 5, 2, 99, 96, 94, 91, 23, 22, 20, 17, 29, 28, 30, 65, 71]
nn_idx: [57, 56, 53, 49, 39, 37, 35, 33, 34, 36, 12, 9, 5, 2, 0, 97, 94, 92, 24, 23, 20, 17, 29, 28, 30, 65, 71]
nn_idx: [57, 56, 53, 49, 39, 37, 35, 33, 34, 36, 12, 9, 5, 2, 0, 97, 94, 92, 24, 23, 20, 17, 29, 28, 30, 65, 71]

[0.5682692307692307, 0.7170868347338936, 0.9206689536878216, 0.7362956810631229, 0.7212121212121212]
16 nn_idx: [1, 99, 97, 95, 92, 89, 87, 68, 67, 66, 64, 62, 55, 58, 59, 60, 57, 56, 54, 53, 52, 50, 48, 46, 44, 42, 40, 35, 33, 23, 22, 21, 70, 82, 81, 77, 78, 11, 12, 10, 8, 5, 2]
nn_idx: [1, 99, 97, 95, 92, 89, 87, 68, 67, 66, 64, 62, 55, 58, 59, 60, 57, 56, 54, 53, 52, 50, 48, 46, 44, 42, 40, 35, 33, 23, 22, 21, 70, 82, 81, 78, 77, 11, 12, 10, 8, 5, 2]
nn_idx: [1, 99, 97, 95, 92, 89, 87, 68, 67, 66, 64, 62, 55, 58, 59, 60, 57, 56, 54, 53, 52, 50, 48, 46, 44, 42, 40, 35, 33, 23, 22, 21, 70, 82, 81, 78, 77, 11, 12, 10, 8, 5, 2]
nn_idx: [99, 97, 95, 93, 90, 87, 88, 68, 67, 65, 63, 60, 59, 56, 54, 52, 51, 48, 46, 44, 38, 37, 15, 16, 17, 32, 30, 28, 26, 24, 23, 21, 22, 86, 73, 82, 79, 78, 9, 10, 7, 5, 1]
nn_idx: [99, 97, 95, 93, 90, 87, 88, 68, 67, 65, 63, 60, 59, 56, 54, 52, 50, 48, 46, 44, 38, 37, 15, 16, 17, 32, 30, 28, 26, 24, 22, 21, 20, 85, 74, 82, 79, 78, 9, 8, 7, 5, 1]
nn_idx: [99, 98, 95, 93, 90, 88, 87, 68, 67, 65, 63, 60, 59, 56, 54, 52, 50, 48, 46, 44, 38, 37, 15, 16, 17, 32, 30, 28, 26, 24, 22, 21, 20, 85, 74, 82, 79, 78, 9, 8, 7, 5, 1]
nn_idx: [99, 98, 95, 93, 90, 88, 87, 68, 67, 65, 63, 60, 59, 56, 54, 52, 50, 48, 46, 44, 38, 37, 15, 16, 17, 32, 30, 28, 26, 24, 22, 21, 20, 85, 74, 82, 79, 78, 9, 8, 7, 5, 1]
nn_idx: [5, 2, 98, 94, 90, 85, 81, 77, 74, 68, 65, 62, 58, 54, 50, 46, 43, 39, 36, 32, 28, 23, 19, 15, 13, 10, 7]
nn_idx: [5, 1, 98, 94, 90, 85, 82, 77, 74, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 15, 13, 10, 7]
nn_idx: [5, 1, 97, 93, 90, 85, 82, 77, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 15, 13, 10, 7]
nn_idx: [5, 1, 97, 93, 90, 86, 82, 77, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 15, 13, 10, 7]
nn_idx: [5, 1, 97, 93, 90, 86, 82, 77, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 15, 13, 10, 6]
nn_idx: [5, 1, 97, 93, 90, 86, 82, 77, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 17, 13, 10, 6]
nn_idx: [5, 1, 97, 93, 90, 86, 82, 76, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 23, 20, 17, 13, 10, 6]
nn_idx: [5, 0, 97, 93, 90, 86, 82, 76, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 24, 20, 17, 13, 10, 6]
nn_idx: [4, 0, 97, 93, 90, 86, 82, 76, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 24, 20, 17, 13, 10, 6]
nn_idx: [4, 0, 97, 93, 90, 86, 82, 76, 73, 68, 65, 62, 57, 53, 50, 46, 43, 40, 36, 32, 28, 24, 20, 17, 13, 9, 6]
nn_idx: [4, 0, 97, 93, 90, 86, 82, 76, 73, 68, 65, 61, 57, 53, 50, 46, 43, 40, 36, 32, 28, 24, 20, 17, 13, 9, 5]
nn_idx: [4, 0, 97, 93, 90, 86, 82, 76, 73, 68, 65, 61, 57, 53, 50, 46, 43, 40, 36, 32, 28, 24, 20, 17, 13, 9, 5]
[0.5980769230769231, 0.7391304347826086, 0.66852487135506, 0.7495847176079734, 0.8763636363636363]
17 [0.6302884615384615, 0.9755244755244755, 0.7805944055944056, 0.7447552447552448, 0.7298951048951049]
18 nn_idx: [4, 2, 0, 98, 95, 93, 91, 88, 87, 82, 81, 80, 70, 75, 76, 77, 74, 73, 71, 69, 68, 66, 63, 62, 60, 59, 58, 49, 46, 47, 31, 27, 25, 21, 19, 16, 15, 13, 11, 10, 9, 7, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 90, 88, 86, 82, 81, 80, 70, 75, 76, 77, 74, 73, 72, 71, 69, 66, 64, 62, 60, 59, 57, 49, 46, 32, 31, 27, 25, 22, 20, 17, 16, 14, 12, 11, 9, 6, 5]
nn_idx: [4, 2, 0, 98, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 64, 62, 60, 59, 57, 48, 46, 32, 33, 26, 25, 22, 20, 17, 16, 14, 12, 11, 9, 6, 5]
nn_idx: [4, 2, 0, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 64, 62, 61, 59, 57, 48, 46, 32, 34, 26, 25, 22, 20, 17, 16, 14, 12, 11, 9, 6, 5]
nn_idx: [3, 2, 0, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 62, 61, 59, 57, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 14, 12, 11, 9, 6, 4]
nn_idx: [3, 2, 0, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 62, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 14, 13, 11, 8, 6, 4]
nn_idx: [3, 2, 0, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 63, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 15, 13, 11, 8, 6, 4]
nn_idx: [3, 1, 0, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 63, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 15, 13, 11, 8, 6, 4]
nn_idx: [3, 1, 99, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 63, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 15, 13, 11, 8, 5, 4]
nn_idx: [3, 1, 99, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 63, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 15, 13, 12, 8, 5, 4]
nn_idx: [3, 1, 99, 97, 95, 93, 90, 88, 86, 82, 81, 80, 74, 75, 76, 77, 73, 72, 71, 70, 69, 67, 65, 63, 61, 59, 58, 46, 47, 32, 34, 26, 25, 22, 20, 17, 16, 15, 13, 12, 8, 5, 4]

nn_idx: [3, 0, 98, 96, 94, 92, 89, 87, 85, 82, 80, 78, 75, 73, 70, 68, 66, 64, 62, 59, 57, 54, 53, 50, 48, 46, 44, 41, 38, 36, 32, 30, 28, 26, 23, 20, 18, 16, 13, 11, 9, 7, 4]
nn_idx: [3, 0, 98, 96, 94, 92, 89, 87, 85, 82, 80, 78, 75, 73, 70, 68, 66, 63, 62, 59, 57, 55, 53, 50, 48, 46, 44, 41, 38, 36, 33, 30, 28, 26, 23, 20, 18, 16, 13, 11, 9, 7, 4]
nn_idx: [3, 0, 98, 96, 94, 92, 89, 87, 85, 82, 80, 78, 75, 73, 70, 68, 66, 63, 62, 59, 57, 55, 53, 50, 48, 46, 44, 41, 38, 36, 33, 30, 28, 26, 23, 20, 18, 16, 13, 11, 9, 7, 4]

[0.5600961538461539, 0.6913525498891353, 0.7212692967409948, 0.9194352159468439, 0.6745011086474502]
19 nn_idx: [98, 96, 94, 92, 90, 88, 85, 83, 80, 78, 75, 73, 70, 66, 65, 63, 61, 58, 56, 54, 52, 50, 48, 46, 45, 43, 39, 36, 34, 31, 28, 25, 23, 20, 18, 15, 14, 11, 10, 7, 5, 2, 99]
nn_idx: [98, 96, 94, 92, 90, 88, 85, 82, 80, 78, 75, 72, 69, 66, 64, 63, 61, 58, 56, 54, 52, 50, 48, 46, 45, 43, 39, 36, 34, 31, 28, 25, 23, 20, 18, 15, 14, 11, 10, 7, 5, 2, 99]
nn_idx: [98, 96, 94, 92, 90, 88, 85, 82, 80, 78, 75, 72, 69, 66, 64, 63, 61, 58, 56, 54, 52, 50, 48, 46, 45, 43, 39, 36, 34, 31, 28, 25, 23, 20, 18, 15, 14, 11, 10, 7, 5, 2, 99]

nn_idx: [96, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 55, 52, 51, 49, 46, 39, 38, 37, 36, 34, 33, 32, 69, 68, 71, 29, 28, 27, 14, 23, 21, 19, 17, 15, 12, 10, 4, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 55, 53, 51, 50, 48, 46, 38, 37, 36, 34, 33, 32, 69, 68, 71, 72, 29, 28, 26, 24, 21, 19, 17, 15, 12, 10, 4, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 55, 54, 52, 50, 48, 46, 38, 37, 36, 34, 33, 32, 69, 68, 71, 72, 29, 28, 26, 24, 21, 19, 17, 15, 12, 11, 5, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 56, 54, 52, 50, 48, 46, 38, 37, 36, 34, 33, 32, 69, 68, 71, 72, 29, 28, 26, 24, 21, 19, 17, 14, 12, 11, 5, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 56, 54, 52, 50, 49, 46, 38, 37, 36, 34, 33, 32, 68, 69, 71, 72, 29, 28, 26, 24, 21, 19, 17, 14, 12, 11, 5, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 56, 54, 52, 51, 49, 46, 38, 37, 36, 34, 33, 32, 68, 69, 71, 72, 29, 28, 26, 24, 21, 19, 17, 14, 12, 11, 5, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 56, 54, 52, 51, 49, 47, 38, 37, 36, 34, 33, 32, 68, 69, 71, 72, 29, 28, 26, 24, 21, 19, 17, 14, 12, 11, 5, 1, 98]
nn_idx: [97, 94, 93, 91, 89, 86, 84, 81, 78, 77, 76, 63, 62, 60, 56, 54, 52, 51, 49, 47, 38, 37, 36, 34, 33, 32, 68, 69, 71, 72, 29, 28, 26, 24, 21, 19, 17, 14, 12, 11, 5, 1, 98]

nn_idx: [60, 55, 51, 47, 38, 35, 32, 29, 31, 33, 8, 7, 3, 98, 94, 91, 89, 85, 84, 17, 16, 26, 25, 24, 27, 62, 61]
nn_idx: [56, 54, 51, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 95, 92, 89, 86, 85, 18, 16, 14, 26, 24, 25, 61, 62]
nn_idx: [56, 54, 51, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 95, 92, 90, 86, 85, 18, 16, 14, 25, 24, 26, 61, 64]
nn_idx: [56, 53, 51, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 95, 93, 90, 87, 85, 18, 16, 14, 26, 24, 25, 61, 64]
nn_idx: [55, 53, 51, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 95, 93, 91, 87, 86, 19, 16, 14, 26, 24, 25, 61, 64]
nn_idx: [55, 53, 50, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 95, 93, 91, 88, 20, 19, 16, 14, 26, 24, 25, 61, 64]
nn_idx: [55, 53, 50, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 96, 93, 91, 88, 20, 19, 16, 14, 26, 24, 25, 61, 65]
nn_idx: [55, 53, 50, 47, 37, 34, 32, 29, 31, 33, 9, 6, 2, 98, 96, 93, 91, 88, 20, 19, 16, 14, 26, 24, 25, 61, 65]

[0.5557692307692308, 0.7969924812030076, 0.9343910806174958, 0.7333887043189369, 0.7284848484848485]
20 [0.5264423076923077, 0.9525166191832859, 0.8442545109211776, 0.8190883190883191, 0.8143399810066476]
21 nn_idx: [1, 100, 98, 96, 94, 92, 76, 75, 74, 72, 69, 67, 65, 63, 61, 59, 57, 56, 53, 51, 46, 44, 20, 21, 40, 38, 36, 35, 33, 31, 29, 28, 27, 26, 97, 88, 86, 82, 83, 13, 11, 4, 2]
nn_idx: [1, 100, 99, 97, 94, 92, 76, 75, 74, 72, 69, 67, 65, 63, 60, 59, 57, 56, 53, 51, 46, 43, 20, 21, 40, 38, 36, 35, 34, 31, 29, 27, 26, 28, 25, 98, 86, 83, 84, 12, 10, 6, 3]
nn_idx: [2, 0, 99, 97, 94, 92, 76, 75, 74, 72, 69, 66, 64, 63, 60, 59, 57, 56, 53, 51, 45, 43, 20, 21, 40, 38, 37, 35, 34, 31, 29, 27, 26, 28, 25, 1, 85, 83, 84, 12, 10, 8, 3]
nn_idx: [2, 0, 100, 98, 94, 92, 76, 75, 74, 72, 69, 66, 64, 62, 60, 59, 57, 56, 53, 51, 45, 43, 20, 21, 40, 38, 37, 35, 34, 31, 29, 27, 26, 28, 25, 1, 84, 83, 12, 13, 10, 8, 4]
nn_idx: [3, 1, 100, 98, 94, 92, 76, 75, 74, 72, 69, 66, 64, 63, 60, 59, 57, 56, 53, 51, 45, 43, 20, 21, 40, 38, 37, 35, 34, 31, 29, 27, 26, 28, 25, 2, 84, 83, 13, 12, 10, 8, 4]
nn_idx: [3, 1, 100, 98, 94, 92, 76, 75, 74, 72, 69, 66, 64, 63, 60, 59, 57, 56, 53, 51, 45, 43, 20, 21, 40, 38, 37, 35, 34, 31, 29, 26, 25, 28, 27, 2, 84, 83, 13, 12, 10, 8, 4]
nn_idx: [3, 1, 100, 98, 94, 92, 76, 75, 74, 72, 69, 66, 64, 63, 60, 59, 57, 56, 53, 51, 45, 43, 20, 21, 40, 38, 37, 35, 34, 31, 29, 26, 25, 28, 27, 2, 84, 83, 13, 12, 10, 8, 4]
nn_idx: [8, 3, 0, 97, 94, 91, 87, 82, 79, 75, 72, 69, 64, 61, 57, 53, 50, 46, 41, 38, 34, 29, 26, 21, 17, 13, 9]
nn_idx: [8, 3, 0, 97, 94, 91, 87, 82, 79, 75, 73, 69, 64, 61, 57, 53, 50, 46, 41, 38, 34, 29, 26, 22, 17, 13, 9]
nn_idx: [7, 3, 0, 97, 94, 91, 87, 82, 79, 75, 73, 69, 64, 61, 57, 53, 50, 46, 41, 38, 34, 29, 26, 22, 17, 13, 9]
nn_idx: [7, 3, 0, 97, 94, 91, 87, 82, 79, 75, 73, 69, 64, 61, 57, 53, 50, 46, 41, 38, 34, 29, 26, 22, 17, 13, 9]

[0.6288461538461538, 0.736904761904762, 0.6916666666666667, 0.7134551495016611, 0.8896969696969697]
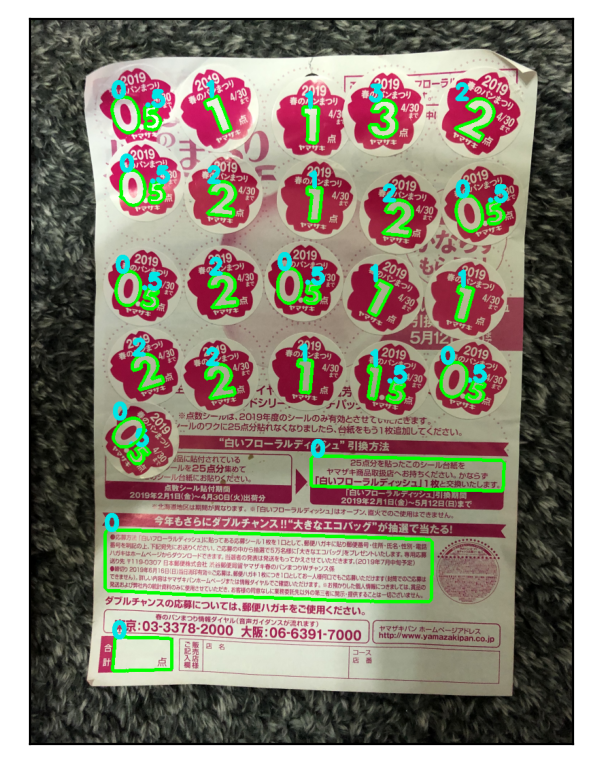
Score: 26.0

今まで通り、正しく点数が認識できました。
本当はここまで来るのにデバッグが大変でしたが…
ということで、デバッグ表示を外して、処理時間を見てみます。
処理時間計測
以下の2つはデバッグ表示を外したもの。
def calc_harupan(img, templates, svm): ctrs, resized_img = detect_candidate_contours(img, sat_th=50) # print('Number of candidates: ', len(ctrs)) if len(ctrs) == 0: return 0.0, resized_img subctrs, _, _ = refine_contours(resized_img, ctrs) subctr_datasets = [contour_dataset(ctr) for ctr in subctrs] ######## #### Simple code similarities = [get_similarities(d, templates)[0] for d in subctr_datasets] #### Code printing progress # similarities = [] # for i,d in enumerate(subctr_datasets): # print(i, end=' ') # similarities += [get_similarities(d, templates)[0]] # print(similarities[-1]) # print('') # print('') ####### _, result = svm.predict(np.array(similarities, 'float32')) result = result.astype('int') score = 0.0 texts = {0:'0', 1:'1', 2:'2', 3:'3', 5:'.5'} font = cv2.FONT_HERSHEY_SIMPLEX for res, ctr in zip(result, ctrs): if res[0] == 5: score += 0.5 elif res[0] != -1: score += res[0] # Annotating recognized numbers for confirmation if res[0] != -1: resized_img = cv2.drawContours(resized_img, [ctr], -1, (0,255,0), 3) x,y,_,_ = cv2.boundingRect(ctr) resized_img = cv2.putText(resized_img, texts[res[0]], (x,y), font, 1, (230,230,0), 5) return score, resized_img
# Find optimum affine matrix using ICP algorithm # src_pts: ndarray, shape is (n_s,2) (n_s: number of points) # dst_pts: ndarray, shape is (n_d,2) (n_d: number of points, n_d should be larger or equal to n_s) # initial_matrix: ndarray, shape is (2,3) # search_range: float number, 0.0 ~ 1.0, the range to search nearest neighbor, 1.0 -> Search in all dst_pts def icp_sub(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]), search_range=0.5): default_affine_matrix = np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]) n_dst = dst_pts.shape[0] n_src = src_pts.shape[0] if n_dst < n_src: # print("icp: Insufficient destination points") return default_affine_matrix, False if initial_matrix.shape != (2,3): print("icp: Illegal shape of initial_matrix") return default_affine_matrix, False n_search = int(n_dst*search_range) M = initial_matrix # Store indices of the nearest neighbor point of dst_pts to the converted point of src_pts nn_idx = [] converged = False for i in range(max_iter): nn_idx_tmp = [] dst_pts_list = [p for p in dst_pts] idx_list = list(range(0,dst_pts.shape[0])) first_pt = True for p in src_pts: # Convert source point with current conversion matrix p2 = M @ np.array([p[0], p[1], 1]) if first_pt: # First point should be searched in all destination points idx, _ = find_nearest_neighbor(dst_pts_list, p2) first_pt = False else: # Search nearest neighbor point in specified range around the last point n = int(min(n_search/2, len(idx_list)/2)) s = max(len(idx_list) + last_idx - n, 0) e = min(len(idx_list) + last_idx + n, 3*len(idx_list)) pts = (dst_pts_list + dst_pts_list + dst_pts_list)[s:e] idx, _ = find_nearest_neighbor(pts, p2) # The index acquired above is counted from 's', so actual index must be recovered idx = (idx + s) % len(idx_list) nn_idx_tmp += [idx_list[idx]] last_idx = idx del dst_pts_list[idx] del idx_list[idx] if nn_idx != [] and nn_idx == nn_idx_tmp: converged = True break dst_pts2 = np.zeros_like(src_pts) for j,idx in enumerate(nn_idx_tmp): dst_pts2[j,:] = dst_pts[idx,:] M = estimate_affine_2d(src_pts, dst_pts2) nn_idx = nn_idx_tmp return M, converged
以下は、timeitで処理時間計測を行う関数。
import timeit def test_harupan_timeit(img, templates, svm): score, result_img = calc_harupan(img, templates, svm) n_loop = 5 result = timeit.timeit('calc_harupan(img, templates, svm)', globals=globals(), number=n_loop) print('Score: ', score) print('Average process time: ', result/n_loop) plt.figure(figsize=(6.4,4.8), dpi=200) plt.imshow(cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)), plt.xticks([]), plt.yticks([]) plt.show() return result/n_loop
今まで使った他の画像も用意して、こちらでも確認を行います。
img2 = cv2.imread('harupan_190428_2.jpg') img3 = cv2.imread('harupan_200317_1.jpg') img4 = cv2.imread('harupan_210227_2.jpg') img5 = cv2.imread('harupan_210402_1.jpg') img6 = cv2.imread('harupan_210402_2.jpg') img7 = cv2.imread('harupan_210414_1.jpg') img8 = cv2.imread('harupan_220330_1.jpg') img9 = cv2.imread('harupan_220330_2.jpg')
いざ実施
imgs = [img1, img2, img3, img4, img5, img6, img7, img8, img9] templates_sel = [0,0,1,2,2,2,2,2,2] ts = [] for img, sel in zip(imgs, templates_sel): if sel == 0: templates = templates2019 elif sel == 1: templates = templates2020 else: templates = templates2021 ts += [test_harupan_timeit(img, templates, svm)] for t in ts: print(t)
Score: 26.0
Average process time: 2.49592544

Score: 26.0
Average process time: 2.86796598

Score: 25.0
Average process time: 1.5119802799999988

Score: 21.5
Average process time: 1.0334361200000004

Score: 28.0
Average process time: 2.0390738799999992

Score: 28.0
Average process time: 1.8528492200000017

Score: 25.0
Average process time: 1.7158804799999985

Score: 24.5
Average process time: 2.49107612

Score: 26.0
Average process time: 2.254828359999999

2.49592544
2.86796598
1.5119802799999988
1.0334361200000004
2.0390738799999992
1.8528492200000017
1.7158804799999985
2.49107612
2.254828359999999
点数の認識はおよそ正しくできていますが、ときどき誤認識があり、また、前回と比較すると、誤認識が増えているようでした。
処理時間は、前回の計測結果が
8.822 vs 7.391 vs 3.412 8.280 vs 6.903 vs 3.605 6.180 vs 3.850 vs 1.558 5.870 vs 2.600 vs 1.461 4.848 vs 3.601 vs 2.703 4.439 vs 3.107 vs 2.976 4.840 vs 3.779 vs 1.884 3.853 vs 3.112 vs 2.917 6.385 vs 5.484 vs 2.431
という感じ(一番右が最終結果)だったので、速くなるものはそれなりに速くなりましたが、それほど変わらないものもあり。
探索範囲を変えてみる
icp関数のsearch_range引数は、上記では0.5にしましたが、これを小さくして処理時間を確認してみたいと思います。
0.25、つまり全体の1/4ぐらいの範囲での探索で。
def icp(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]])): search_range = 0.25 return icp_sub(src_pts, dst_pts, max_iter=max_iter, initial_matrix=initial_matrix, search_range=search_range)
ts2 = [] for img, sel in zip(imgs, templates_sel): if sel == 0: templates = templates2019 elif sel == 1: templates = templates2020 else: templates = templates2021 ts2 += [test_harupan_timeit(img, templates, svm)] for t1,t2 in zip(ts, ts2): print('{:.3f} vs '.format(t1), '{:.3f}'.format(t2))
Score: 26.0
Average process time: 2.2573845800000014

Score: 26.0
Average process time: 2.5589878199999987

Score: 25.0
Average process time: 1.2015617599999984

Score: 21.5
Average process time: 0.8892099600000052

Score: 28.0
Average process time: 1.5628163000000028

Score: 28.0
Average process time: 1.5231709799999975

Score: 25.0
Average process time: 1.172573319999998

Score: 25.5
Average process time: 1.5129594800000006

Score: 26.0
Average process time: 1.5159665599999983

2.496 vs 2.257
2.868 vs 2.559
1.512 vs 1.202
1.033 vs 0.889
2.039 vs 1.563
1.853 vs 1.523
1.716 vs 1.173
2.491 vs 1.513
2.255 vs 1.516
点数認識のほうはそれほど変わらず。処理時間は、最後の2つは比較的速くなり、それ以外はあまり変わっていません。
もう1パターンくらいやってみる。
0.1ぐらいでどうか。
def icp(src_pts, dst_pts, max_iter=20, initial_matrix=np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]])): search_range = 0.1 return icp_sub(src_pts, dst_pts, max_iter=max_iter, initial_matrix=initial_matrix, search_range=search_range)
ts3 = [] for img, sel in zip(imgs, templates_sel): if sel == 0: templates = templates2019 elif sel == 1: templates = templates2020 else: templates = templates2021 ts3 += [test_harupan_timeit(img, templates, svm)] for t1,t2,t3 in zip(ts, ts2, ts3): print('{:.3f} vs '.format(t1), '{:.3f} vs '.format(t2), '{:3f}'.format(t3))
Score: 25.5
Average process time: 1.581251139999995

Score: 25.5
Average process time: 2.0109177600000065

Score: 25.0
Average process time: 0.9684285799999998

Score: 31.5
Average process time: 0.7069887800000061

Score: 36.5
Average process time: 1.2002911400000016

Score: 42.0
Average process time: 1.0803001199999926

Score: 26.0
Average process time: 1.0018412399999987

Score: 34.0
Average process time: 1.1885020799999892

Score: 26.5
Average process time: 1.2393877799999928

2.496 vs 2.257 vs 1.581251
2.868 vs 2.559 vs 2.010918
1.512 vs 1.202 vs 0.968429
1.033 vs 0.889 vs 0.706989
2.039 vs 1.563 vs 1.200291
1.853 vs 1.523 vs 1.080300
1.716 vs 1.173 vs 1.001841
2.491 vs 1.513 vs 1.188502
2.255 vs 1.516 vs 1.239388
処理は速くなっていますが、誤認識も結構増えてしまっている感じです。
0.1はやり過ぎかな。
以上
ICP処理の見直しで、ある程度処理を高速化することができました。
次回、PCカメラ画像からのリアルタイム処理に再チャレンジしてみたいと思います。
今度こそ最終回になるか…?