OpenCVチュートリアルの続きです。
OpenCVにおける輪郭(領域) — OpenCV-Python Tutorials 1 documentation
とりあえず輪郭検出、表示
cv2.findContours()関数で、輪郭を検出することができます。
詳細はともかく、やってみます。
2値画像に対しての処理となること、白い物体と黒い背景があり、物体の輪郭を検出するということで、2値化のチュートリアルのところでやった画像を使ってみます。
HSV値からシール領域、台紙領域(および点数数字)を検出したものです。
import cv2
img1 = cv2.imread('harupan_200317_1.jpg')
img1 = cv2.resize(img1, None, fx=0.1, fy=0.1, interpolation=cv2.INTER_AREA)
img1_hsv = cv2.cvtColor(img1, cv2.COLOR_BGR2HSV)
ret, img1_seal = cv2.threshold(img1_hsv[:,:,0], 160, 255, cv2.THRESH_BINARY)
ret, img1_card = cv2.threshold(img1_hsv[:,:,1], 50, 255, cv2.THRESH_BINARY_INV)
from matplotlib import pyplot as plt
plt.subplot(121), plt.imshow(img1_seal, cmap='gray'), plt.title('Seal area'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img1_card, cmap='gray'), plt.title('Card area'), plt.xticks([]), plt.yticks([])
plt.show()

この画像でcv2.findContours()関数を実行、cv2.drawContours()関数で輪郭を表示します。
img1_seal_cp = img1_seal
img1_card_cp = img1_card
img1_seal_contours, img1_seal_hierarchy = cv2.findContours(img1_seal_cp, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
img1_card_contours, img1_card_hierarchy = cv2.findContours(img1_card_cp, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
img1_seal_ctrs = cv2.drawContours(img1.copy(), img1_seal_contours, -1, (0,255,0), 2)
img1_card_ctrs = cv2.drawContours(img1.copy(), img1_card_contours, -1, (255,0,0), 3)
img1_seal_ctrs = cv2.cvtColor(img1_seal_ctrs, cv2.COLOR_BGR2RGB)
img1_card_ctrs = cv2.cvtColor(img1_card_ctrs, cv2.COLOR_BGR2RGB)
plt.subplot(121), plt.imshow(img1_seal_ctrs), plt.title('Seal contours'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img1_card_ctrs), plt.title('Card contours'), plt.xticks([]), plt.yticks([])
plt.show()
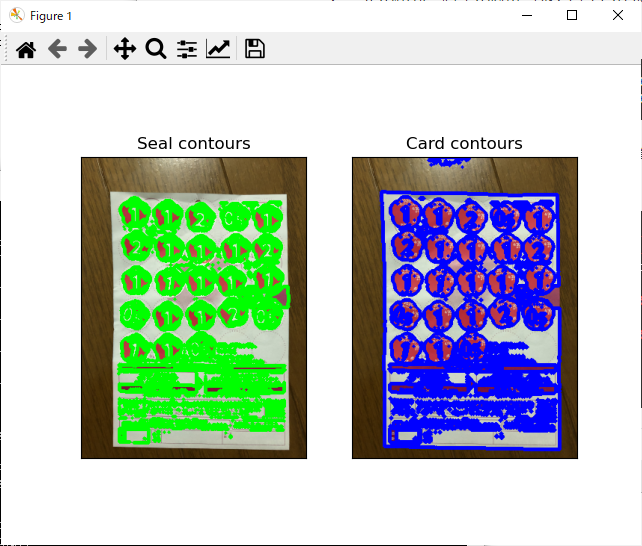
シールや台紙の輪郭はとれていそうですが、細かい余計な輪郭も出ているようです。
いくつか気づき点等。
- 今回の環境では
cv2.findContours()関数の戻り値はcontours, hierarchyの2つだけでした。OpenCVのバージョンによるのか?
以下のサイトではこの戻り値2つのパターンで記載されていました。
OpenCV - findContours で画像から輪郭を抽出する方法 - pystyle
cv2.drawContours()関数では、引数の画像に上書きしてしまうようです。輪郭画像を元の画像に重ねるとき、元の画像をコピーしています。画像のコピーは、単純な代入だと参照になるようだったので、copy()関数を使います。- カラー画像表示の際、OpenCVではBGRフォーマット、matplotlibではRGBフォーマットで扱われるので、変換しています。
輪郭の特徴
輪郭の面積や周長を出せるようなので、これでほしい輪郭だけフィルタリングすることができるのでは?
まず面積
シール領域画像、台紙領域画像からの輪郭の面積の分布がどうなっているかを調べてみます。
img1_seal_areas = []
for ctr in img1_seal_contours:
img1_seal_areas += [cv2.contourArea(ctr)]
img1_card_areas = []
for ctr in img1_card_contours:
img1_card_areas += [cv2.contourArea(ctr)]
以下のように、輪郭面積の範囲を確認しながら、ヒストグラムを見てみました。
>>> max(img1_seal_areas)
1496.0
>>> plt.hist(img1_seal_areas, 150, [0,1500])
(array([819., 96., 34., 30., 12., 2., 5., 1., 0., 0., 0.,
0., 1., 1., 4., 7., 3., 0., 1., 1., 0., 0.,
2., 1., 1., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 2.,
0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 1.,
0., 0., 1., 0., 0., 0., 0., 2., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 1., 0., 1., 2., 0., 1., 1.,
0., 2., 0., 1., 2., 1., 1., 0., 0., 1., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 1.]), array([ 0., 10., 20., 30., 40., 50., 60., 70., 80.,
90., 100., 110., 120., 130., 140., 150., 160., 170.,
180., 190., 200., 210., 220., 230., 240., 250., 260.,
270., 280., 290., 300., 310., 320., 330., 340., 350.,
360., 370., 380., 390., 400., 410., 420., 430., 440.,
450., 460., 470., 480., 490., 500., 510., 520., 530.,
540., 550., 560., 570., 580., 590., 600., 610., 620.,
630., 640., 650., 660., 670., 680., 690., 700., 710.,
720., 730., 740., 750., 760., 770., 780., 790., 800.,
810., 820., 830., 840., 850., 860., 870., 880., 890.,
900., 910., 920., 930., 940., 950., 960., 970., 980.,
990., 1000., 1010., 1020., 1030., 1040., 1050., 1060., 1070.,
1080., 1090., 1100., 1110., 1120., 1130., 1140., 1150., 1160.,
1170., 1180., 1190., 1200., 1210., 1220., 1230., 1240., 1250.,
1260., 1270., 1280., 1290., 1300., 1310., 1320., 1330., 1340.,
1350., 1360., 1370., 1380., 1390., 1400., 1410., 1420., 1430.,
1440., 1450., 1460., 1470., 1480., 1490., 1500.]), <BarContainer object of 150 artists>)
>>>
>>> max(img1_card_areas)
79053.5
>>> plt.hist(img1_card_areas, 80, [0, 80000])
(array([971., 26., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1.]), array([ 0., 1000., 2000., 3000., 4000., 5000., 6000., 7000.,
8000., 9000., 10000., 11000., 12000., 13000., 14000., 15000.,
16000., 17000., 18000., 19000., 20000., 21000., 22000., 23000.,
24000., 25000., 26000., 27000., 28000., 29000., 30000., 31000.,
32000., 33000., 34000., 35000., 36000., 37000., 38000., 39000.,
40000., 41000., 42000., 43000., 44000., 45000., 46000., 47000.,
48000., 49000., 50000., 51000., 52000., 53000., 54000., 55000.,
56000., 57000., 58000., 59000., 60000., 61000., 62000., 63000.,
64000., 65000., 66000., 67000., 68000., 69000., 70000., 71000.,
72000., 73000., 74000., 75000., 76000., 77000., 78000., 79000.,
80000.]), <BarContainer object of 80 artists>)
台紙領域画像からの輪郭で、大きな輪郭が1つ見られます。
これが台紙全体の輪郭ではないかと期待されるので、見てみます。
for ctr in img1_card_contours:
if cv2.contourArea(ctr) > 79000:
img1_card_contour_largest += [ctr]
img1_card_ctrs = cv2.drawContours(img1.copy(), img1_card_contour_largest, 1, (255,0,0), 3)
cv2.imshow('Card contours', img1_card_ctrs)

予想通りです。
射影変換用の角の4点検出に使えそうな感じがします。
後はシール領域、また、数字の輪郭を検出したい。
ヒストグラムを今度はもう少し細かく見てみます。
>>> plt.hist(img1_seal_areas, 100, [0,100])
(array([408., 51., 144., 24., 69., 26., 29., 21., 33., 14., 18.,
21., 11., 12., 6., 7., 4., 6., 7., 4., 6., 5.,
4., 5., 2., 1., 2., 5., 3., 1., 3., 6., 5.,
2., 1., 2., 4., 1., 2., 4., 1., 2., 2., 2.,
2., 1., 0., 1., 0., 1., 0., 0., 1., 0., 0.,
0., 0., 0., 1., 0., 1., 1., 0., 0., 2., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.]), array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.,
11., 12., 13., 14., 15., 16., 17., 18., 19., 20., 21.,
22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32.,
33., 34., 35., 36., 37., 38., 39., 40., 41., 42., 43.,
44., 45., 46., 47., 48., 49., 50., 51., 52., 53., 54.,
55., 56., 57., 58., 59., 60., 61., 62., 63., 64., 65.,
66., 67., 68., 69., 70., 71., 72., 73., 74., 75., 76.,
77., 78., 79., 80., 81., 82., 83., 84., 85., 86., 87.,
88., 89., 90., 91., 92., 93., 94., 95., 96., 97., 98.,
99., 100.]), <BarContainer object of 100 artists>)
>>> plt.hist(img1_card_areas, 100, [0,2000])
(array([869., 49., 11., 20., 6., 2., 3., 1., 0., 4., 1.,
0., 0., 1., 0., 0., 1., 1., 0., 0., 0., 0.,
0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 4., 4., 5., 6., 4., 1., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0.]), array([ 0., 20., 40., 60., 80., 100., 120., 140., 160.,
180., 200., 220., 240., 260., 280., 300., 320., 340.,
360., 380., 400., 420., 440., 460., 480., 500., 520.,
540., 560., 580., 600., 620., 640., 660., 680., 700.,
720., 740., 760., 780., 800., 820., 840., 860., 880.,
900., 920., 940., 960., 980., 1000., 1020., 1040., 1060.,
1080., 1100., 1120., 1140., 1160., 1180., 1200., 1220., 1240.,
1260., 1280., 1300., 1320., 1340., 1360., 1380., 1400., 1420.,
1440., 1460., 1480., 1500., 1520., 1540., 1560., 1580., 1600.,
1620., 1640., 1660., 1680., 1700., 1720., 1740., 1760., 1780.,
1800., 1820., 1840., 1860., 1880., 1900., 1920., 1940., 1960.,
1980., 2000.]), <BarContainer object of 100 artists>)
やっぱり台紙領域画像からの輪郭のほうが分かりやすそうで、面積1000以上に分布している25個の輪郭がシール輪郭に当たるのではと考えられます。(実際にはシールは23個しかないので、2個は違うものです。)
img1_card_contours_seal = []
for ctr in img1_card_contours:
if 2000 > cv2.contourArea(ctr) > 1000:
img1_card_contours_seal += [ctr]
img1_card_ctrs = cv2.drawContours(img1.copy(), img1_card_contours_seal, -1, (255,0,0), 3)
cv2.imshow('Card contours', img1_card_ctrs)

これもおよそ予想通り、いい感じです。
シールではない2つの輪郭は、台紙の下のほうの四角い領域でした。
最小外接円で円形領域を探す
シール領域画像の輪郭があまり使えていないので、なんとかならないかと。
シールの輪郭はだいたい円形をしているので、最小外接円との面積の差が小さいもの、で探すことができるのでは?と考えました。
img1_seal_ratios = []
for ctr in img1_seal_contours:
(x, y), radius = cv2.minEnclosingCircle(ctr)
img1_seal_ratios += [cv2.contourArea(ctr) / (radius*radius*np.pi)]
>>> max(img1_seal_ratios)
0.8911880248803259
>>> plt.hist(img1_seal_ratios, 100, [0, 1.0])
(array([367., 0., 0., 1., 1., 1., 8., 6., 4., 3., 6.,
9., 12., 4., 6., 6., 1., 4., 5., 5., 3., 3.,
4., 4., 4., 7., 6., 4., 3., 3., 6., 39., 3.,
0., 4., 6., 8., 7., 18., 8., 13., 1., 3., 0.,
7., 6., 3., 24., 3., 2., 11., 2., 5., 5., 6.,
10., 74., 8., 1., 3., 5., 15., 3., 160., 2., 2.,
2., 9., 1., 1., 18., 3., 1., 9., 12., 3., 0.,
1., 3., 5., 3., 3., 4., 2., 0., 1., 2., 0.,
0., 4., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.]), array([0. , 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1 ,
0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.2 , 0.21,
0.22, 0.23, 0.24, 0.25, 0.26, 0.27, 0.28, 0.29, 0.3 , 0.31, 0.32,
0.33, 0.34, 0.35, 0.36, 0.37, 0.38, 0.39, 0.4 , 0.41, 0.42, 0.43,
0.44, 0.45, 0.46, 0.47, 0.48, 0.49, 0.5 , 0.51, 0.52, 0.53, 0.54,
0.55, 0.56, 0.57, 0.58, 0.59, 0.6 , 0.61, 0.62, 0.63, 0.64, 0.65,
0.66, 0.67, 0.68, 0.69, 0.7 , 0.71, 0.72, 0.73, 0.74, 0.75, 0.76,
0.77, 0.78, 0.79, 0.8 , 0.81, 0.82, 0.83, 0.84, 0.85, 0.86, 0.87,
0.88, 0.89, 0.9 , 0.91, 0.92, 0.93, 0.94, 0.95, 0.96, 0.97, 0.98,
0.99, 1. ]), <BarContainer object of 100 artists>)
これまた微妙な分布…
とりあえず面積比率の大きい(外接円との面積の差が小さい)ものをいくつかを取ってみたいと思います。
img1_seal_contours_seal = []
for i in range(len(img1_seal_contours)):
if img1_seal_ratios[i] > 0.77:
img1_seal_contours_seal += [img1_seal_contours[i]]
img1_seal_ctrs = cv2.drawContours(img1.copy(), img1_seal_contours_seal, -1, (0,255,0), 3)
cv2.imshow("Seal contours", img1_seal_ctrs)

やっぱりいまいちですが、このやり方も使い道はありそうです。
そもそもシール領域画像にもう少し前処理が必要だったかもしれません。
以上
今回はここまでにします。
あっという間に春のパン祭りが終わってしまった…
来年に生かせればいいな。